This blog post is briefing my coding phase 1 in Jenkins Machine Learning Plugin for this GSoC 2020.
After a fresh introduction of community bonding, On June 1st, coding of GSoC had started officially with phase 1. At this point, every GSoC student should be expected to have a rigid plan with their entire project. With the guidance of mentors I was able to complete a design document and timeline which can be slightly adjustable during the coding. The coding phase was more about coding and discussion.
Quick review
Week 1
I have to ensure that I have a solid architecture for implementing the core of this plugin such that perhaps I or future community will be able to develop R and Julia kernels for this plugin. Factory method design patterns are suitable when users need different types of products ( Python, R and Julia) without knowing much about the internal infrastructure ( Manager of these interpreters ).
All the base classes were implemented this week.
Design the Kernel connectors
Initiate the interpreter
Close the connection
Add simple tests
Update pom.xml
More than these changes, repo was updated with pull request template and licence header. Readme was extended a little at the end of the week.
Issues and Challenges
Git rebase and squash
Tests invokes ipython client in the server failed during the CI build
Week 2
With the help of a design document, I had a plan to do the configurations globally and using the Abstract Folder property I could save the configuration and retrieve for the job configuartion. I used to reference some other well developed plugin for the structure of code. That helped me a lot while I was coding. Our first official contributor has popped out his pull request.
Form validations and helper html will be a great help in the user point of view as well as developers. A minor bug was fixed with the guidance of mentors by writing tests with ‘Jenkins WebClient`. Until the end of the week, builder class of the plugin has been implemented with lots of research and discussion. Finally, Test connection was added to the global configuration page to start the connection and test it. A single issue that blocked me using py4j authentication about zeppelin-python was reported in Jira.
Issues and challenges
Backend depends on Apache zeppelin-python API to connect IPython
Find relevant extension points to extend the plugin
Week 3
Earlier in this week, we were trying to merge our IPython builder PR without any memory leaks or bugs that will cause the system to be devastating while running this plugin. Later, this whole week I was implementing a file parser that could copy the necessary files and had the ability to accomplish the file conversion.
Supported file types
Python (.py)
JSON (Zeppelin notebooks format)
IPython builder was able to run Jupyter Notebooks and Zeppelin formatted JSON files at the end of the 3rd week. Minor issues were fixed in the code. We used ANSI color plugin to fix the abnormal view of error messages produced by the ipython kernel.
Issues and Challenges
Python error messages could not be displayed in rich format If a job is running at user level, but if the python code access file/file path which is not authorized to the user, it returns a permission denied message. While running on agent, notebook has to be written/copied to agent workspace Artifacts should be maintained/reachable from master after build.
Week 4
As all the major tasks has done, the demo preparation and plan for a experimental release was carried during the last week. There were lots of research on how to connect to a existing kernel in remote. Demo and presentation were prepared along the week.
Issues and Challenges
Releasing the first version was bit late
Knowledge transfer
How to debug the code through IntelliJ
Edit configuration → Add new Configuration → Maven
Command line → type hpi:run
Click the debug icon on the toolbar or go to Run menu then Debug
How to setup to test the plugin
Setup JDK 8 and Maven 3.5.*
Create a directory $ mkdir machine-learning-plugin
Create a virtual environment $ virtualenv venv
Activate your virtual environment $ source venv/bin/activate
With Pride month coming to an end, Databricks’ newest Employee Resource Group, Queeries Network, is looking back at how we celebrated. The mission of this group is to create opportunities to come together to discuss topics important to the LGBTQ+ community, network and build community. To celebrate Pride Month, our Queeries Network Employee Resource Group hosted virtual pride socials, participated in virtual pride parades across the globe, and had dialogues around the history of Pride and the intersections with current events impacting the Black community.
When we look back at how Pride started, from the Stonewall uprising to what is now an international celebration of the LGBTQ+ community and their contributions to the world, there has been a lot of progress in the fight for gay rights and equality, but there is also more we can do.
As we continue this reflection, we’ve asked a few Bricksters, who have made amazing contributions to Databricks, for their thoughts on how we can all create a more inclusive workspace that encourages everyone to bring their authentic self to work. Read more below.
How can we create an environment that encourages everyone to be their authentic self and do their best work?
One of our core values at Databricks is to be customer obsessed, which at first glance, can sound like a narrow and hyperfocused attention to a singular goal. In practice, what I think it actually means is to be genuinely curious about our customers — to struggle along with them in their challenges and to celebrate in their victories. I think the same applies to how we treat each other. Taking the time to be genuinely curious about someone’s lived experience is hard because it requires a willingness to not have all the answers. But when we spend time and energy investing in and learning from each other, that’s when, in my experience, real success is realized.
— Jess Chace (she/her), Customer Success Engineer (New York)
It’s critical to show everyone in the company, particularly the newer members who might have less confidence, that there are many ways to be, to find personal success, and to develop as an individual. Offices are usually pretty homogeneous. We have to raise up the less obvious people in our midst, to showcase the realities and the successes of people of all colours, creeds, kinds, sexual and gender identities. A lot of people I speak to who don’t fit naturally into the white, male, heteronormative milieu will talk about the first time they met someone who was different, but successful in their own way. Someone they wanted to emulate. That’s powerful — to show that there are many paths, all of them perfectly valid. It creates new leaders, and it creates the foundation for the next generation of difference and variety, of authenticity.
— Rob Anderson (he/him), Director of Field Engineering (London)
I start by focusing on the details of things like inclusive language, especially within an interview setting. Those early interactions are some of the most stressful moments in anyone’s life, we shouldn’t make them more difficult. I’ve been particularly thoughtful about my choice of words while answering questions during the hiring process about the challenges of relocating with a partner or family or when discussing parental benefits. I’ve had some people mention, after joining Databricks, how significant these small choices were to them as a signal of our values.
— Stacy Kerkela (she/her), Director of Engineering (Amsterdam)
Creating an environment at work for Bricksters to be their most authentic selves is critical to building an inclusive and collaborative culture. Being “authentic” might seem like a simple concept; however, many individuals from marginalized backgrounds are oftentimes code switching or shrinking pieces of themselves to fit into the majority culture. One of our company values that is most salient to me is: Teamwork makes the dream work. To promote authenticity within the workplace, we should encourage our team members to build genuine connections with one another, amplify our strengths and, most importantly, actively listen and promote empathy — even during challenging or unpredictable times.
As a queer Black femme, who holds many other marginalized identities, oftentimes I am navigating various environments and interacting with diverse audiences and stakeholders. I am always looking to build strong partnerships and bring my authentic self to interactions with candidates, colleagues and executives. Promoting an inclusive environment where trust and vulnerability are at the core is extremely important for me to do my best work and feel supported in doing so.
— Kaamil Al-Hassan (she/her), Talent Acquisition (San Francisco)
How does focusing on nurturing this inclusive environment help us have a greater impact at Databricks and in our communities?
Another one of our core values at Databricks is to let the data decide, and it’s no secret that having a more diverse and inclusive work environment correlates with many positive business outcomes like higher innovation revenues, greater market share and greater returns to shareholders. The true value of promoting diversity and inclusion, however, is so much more than monetary gains. When our work reflects the voices and minds of our actual communities, it is better positioned to serve us all.
— Jess Chace (she/her), Customer Success Engineer (New York)
Databricks is a member of the technology community, where there is a great opportunity to continue to increase the representation of women, ethnic minorities, and people of various ages as well as sexual and gender identities. I believe that we will make the biggest impact by investing in how we hire diverse teams and support the incredible talent from these under-represented groups. There is a lot we can do to have a big impact on our companies and our communities at large.
— Rob Anderson (he/him), Director of Field Engineering (London)
At Databricks, I build teams that I would want to belong to. That means having the safety to be my authentic self and providing that same comfort zone to everyone around me. This year as entire companies have moved to work-from-home models, there’s a lot of visibility into all of our home lives that makes it impossible for me to live less openly. Engaging with teammates via video calls at home can make it difficult to create separate home and work identities, especially for members of the LGBTQ+ community. It is important that we focus on creating an inclusive culture so everyone can feel comfortable and confident being their authentic selves and doing their best work without the stress or anxiety of wondering if they will be accepted. The impact of that care we show for one another and our dedication to inclusion is huge for our entire community.
— Stacy Kerkela (she/her), Director of Engineering (Amsterdam)
Being queer means that every day I am ”coming out.” When I go to the grocery store with my partner, when someone inquires about my ”boyfriend,” or when I attend our company holiday party and my partner is slaying in her tuxedo but is also wearing makeup. Coming out is not a singular moment. Creating an inclusive culture includes feeling supported by my colleagues and exemplifying my authentic queer self.
Our impact will be even greater when we invite members of the LGBTQ+ community to join our global teams through investing in targeted outreach events. Building an inclusive culture means exploring the possibility of gender-neutral bathrooms and encouraging pronoun usage in everyday conversations. I am excited for us to celebrate Pride and for the resilience of this particular community that is still fighting every day for equal rights and visibility. I look forward to getting more involved in the newly formed LGBTQ+ ERG and exploring ways to create inclusivity and highlight the queer experience here at Databricks.
— Kaamil Al-Hassan (she/her), Talent Acquisition (San Francisco)
It was great to launch our Queeries Network Employee Resource Group and celebrate Pride Month together. To learn more about how you can join us, check out the Careers page.
It comes ahead of the start of monsoon season in Rajasthan and surrounding regions, where desert locusts will migrate to over the next few weeks to breed and lay their eggs.
The onset of the pandemic has also accelerated the willingness of small businesses to use technology to scale up operations, opening up a market that had in the past viewed technology companies as a competitor.
DDMRP, which is also known as Demand Driven Requirements Planning is an innovative method available to plan both inventories as well as materials. This can provide a large number of benefits to a company. That’s because a company that adhere to DDMRP will be able to offer products to the market and cater the specific requirements that exist in it. In the meantime, it is also possible to make better actions and decisions at the time of planning as well.Five components of DDMRPWhen you deep dive and take a look at Demand Driven Requirements Planning, you will be able to discover five main components in it. These are sequential components. This sequence and the relationship that exist in between the element refers to position, pull and protection.Here’s a quick overview of the five components:- Strategic inventory positioning This is where you come up with the decision to decouple the points that are placed.- Buffer profile and levelsWhen it comes to buffer profiles and levels, you can figure out the level of protection that is associated with the decoupling points.- ...
Externalizing fingerprint storage for Jenkins is a Google Summer of Code 2020 project. We are working on building a pluggable storage engine for fingerprints (see JEP-226).
File fingerprinting is a way to track which version of a file is being used by a job/build, making dependency tracking easy. The fingerprint engine of Jenkins can track usages of artifacts, credentials, files, etc. within the system. Currently, it does this by maintaining a local XML-based database which leads to dependence on the physical disk of the Jenkins master.
Allowing fingerprint storage to be moved to external storages decreases the dependence of Jenkins instances on the physical disk space and also allows for tracking the flow of fingerprints across instances of Jenkins connected to the same external storage.
Advantages of using external storage drivers:
Remove dependence on Jenkins master disk storage
Can configure pay-as-you-use cloud storages
Easy Backup Management
Better Reliability and Availability
Fingerprints can be tracked across Jenkins instances
Along with this API, we are also working on a reference implementation in the form of a plugin, powered by Redis.
As phase 1 of this project comes to an end, this blog post serves as a summary of the progress we made to the entire Jenkins community.
Current State
The new API introduced in Jenkins core is under review. Once merged, it will offer developers to extend it to build external fingerprint storage plugins.
With PR-4731, we introduce a new fingerprint storage API, allowing configuring custom storage engines. We exposed the following methods in the new FingerprintStorage class:
void save()
Saves the given Fingerprint in the storage.
Fingerprint load(String id)
Returns the Fingerprint with the given unique ID. The unique ID for a fingerprint is defined by Fingerprint#getHashString().
void delete(String id)
Deletes the Fingerprint with the given unique ID.
boolean isReady()
Returns true if there is some data in the fingerprint database corresponding to the particular Jenkins instance.
Click on Submit, and then press the Check Now button.
Go to Available tab.
Search for Redis Fingerprint Storage Plugin and check the box along it.
Click on Install without restart
The plugin should now be installed on your system.
Usage
Once the plugin has been installed, you can configure the Redis server details by following the steps below:
Select Manage Jenkins
Select Configure System
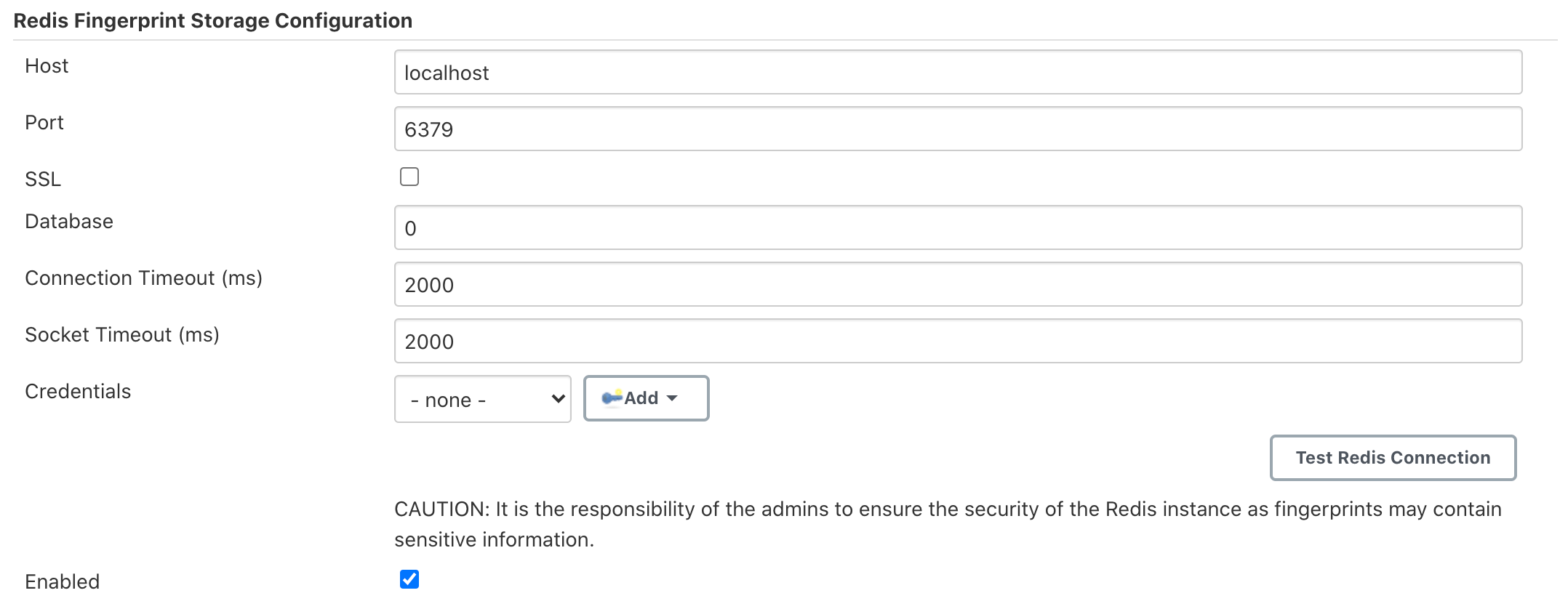
Scroll to the section Redis Fingerprint Storage Configuration and fill in the required details:
Host - Enter hostname where Redis is running
Port - Specify the port on which Redis is running
SSL - Click if SSL is enabled
Database - Redis supports integer indexed databases, which can be specified here.
Connection Timeout - Set the connection timeout duration in milliseconds.
Socked Timeout - Set the socket timeout duration in milliseconds.
Credentials - Configure authentication using username and password to the Redis instance.
Enabled - Check this to enable the plugin (Note: This is likely to be removed very soon, and will be enabled by default.)
Use the Test Redis Connection to verify that the details are correct and Jenkins is able to connect to the Redis instance.
Press the Save button.
Now, all the fingerprints produced by this Jenkins instance should be saved in the configured Redis server!
Future Work
Some of the topics we aim to tackle in the next phases include extending the API, fingerprint cleanup, migrations (internal→external, external→internal, external→external), tracing, ORM, implementing the saveable listener, etc.
In this article, I would like to share some highlights from the User Interface track of the Jenkins UI/UX Hackfest we held on May 25..29. This blog post has been slightly delayed by the infrastructure issues we had in the project, but, as for improving the Jenkins UI, it is better late than never. Key highlights from the event:
We delivered a preview of Jenkins read-only configuration. During the hackfest we discovered and fixed many compatibility issues.
We created a new Dark Theme for Jenkins. We also improved theming support in the core, and fixed compatibility in many plugins.
A read-only view of Jenkins configurations, jobs and agents is important to Jenkins Configuration-as-Code users. It would allow them to access configuration and diagnostics information about their Jenkins instances while having no opportunity to occasionally change it. This story is a part of the Jenkins roadmap, and it was featured as an area for contribution during the UI/UX hackfest.
On May 25th we have released a preview for Read-only Jenkins Configuration. Read the announcement by Tim Jacomb in this blogpost. During the hackfest we kept testing the change and fixing compatibility in the Jenkins plugins, including the Cloud Stats Plugin, Role Strategy Plugin, Simple Disk Usage Plugin and others.
We would appreciate feedback and testing from the Jenkins users! See the blogpost for the guidelines.
Dark user interface themes are very popular among developers: in IDE, communication tools, etc. And there is an interest to have one for Jenkins. There were a few of implementations before the hackfest, most notably camalot/jenkins-dark-stylish and a dark version of the Neo2 Theme. These themes were difficult to maintain, and finally they were either removed or abandoned. What if Jenkins had an official theme?
During the event a group of contributors focused on creating a new Dark Theme for Jenkins. This effort included:
Patches to the Jenkins core which simplified development and maintenance of UI themes. Support for CSS variables was added, as well as PostCSS processing which helps to simplify browser compatibility.
You can try out this theme starting from Jenkins 2.239. It is available as a plugin from the Jenkins Update Center. An example screenshot for the Build console log:
If you discover any Dark theme compatibility issues, please report them here.
Jenkins Web UI accessibility was one of the suggested topics at the event. We would like to make Jenkins usable by as many people as possible. It includes multiple groups of users: people with disabilities, ones using mobile devices, or those with slow network connections. In general, all Jenkins users would benefit from better navigation and layouts. Some of the accessibility improvements we implemented during the event:
Added aria-labels to username & password input fields
Indicate the language of the page in the footer (not merged yet)
Remove page generation timestamp from the footer
At the UI/UX hackfest the major focus was on migrating configuration pages from tables to divs (JENKINS-62437). It will make them more user-friendly on narrow and especially mobile screens. The change will also help users to navigate complex forms with multiple levels of nesting. Our progress:
User Experience testing. Thanks to the contributors, we discovered several compatibility issues in plugins.
Bug fixes in several plugins
A new Dockerized demo which allows to evaluate the change with a set of pre-configured plugins.
Here is an example of a job configuration page using the new layout:
We will keep working on this change in the coming weeks, and we invite Jenkins users and Contributors to help us with testing the change! Testing guidelines are available in the JENKINS-62437 ticket.
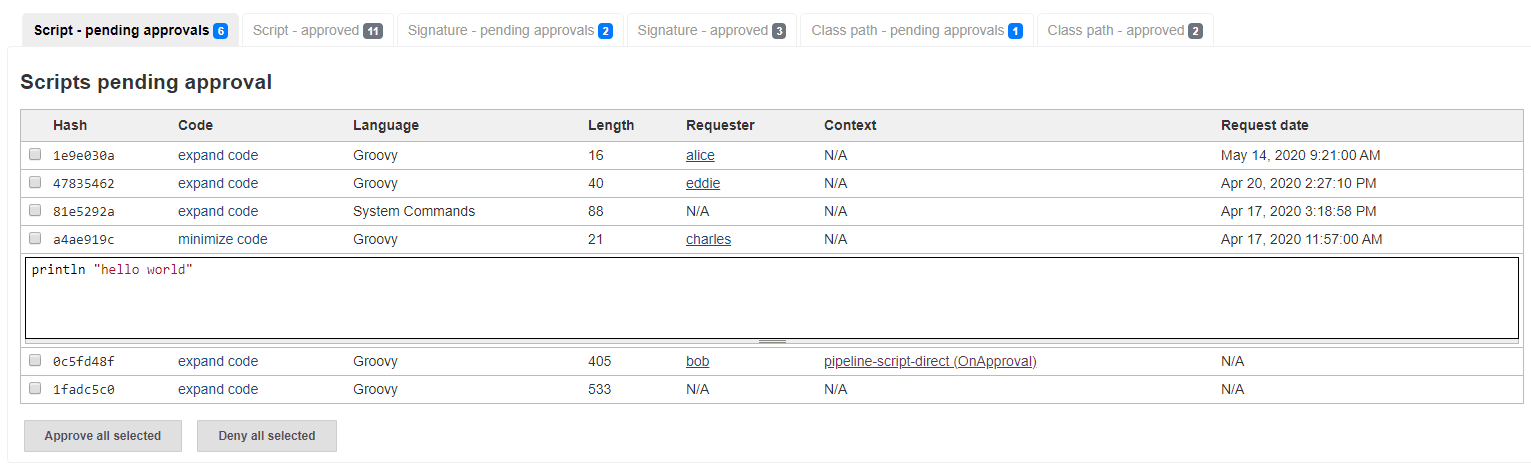
During the hackfest Wadeck Follonier redesigned the script approval interface in the Script Security Plugin. The new UI allows viewing the list of approved scripts, shows the last access timestamp, and allows managing the approvals individually. Before, it was not possible to do it from the Web interface. Once the pull request is released, the feature will become available to Jenkins users.
Other UI improvements
In addition to the major improvements listed above, there were also many smaller patches in the Jenkins core and various plugins. You can find a full list of contributions to the user interface here, some important improvements:
We invite Jenkins users and contributors to join the effort and to improve the user interface together. The Jenkins project gradually adopts modern frontend stacks (JavaScript, React, Gatsby, Vue.js, etc.) and design methodologies. For example, see the presentation about beautifying the UI of Jenkins reporter plugins by Ullrich Hafner. It is a great opportunity for frontend developers to join the project, share their experiences, experiment with new technologies, and improve the Jenkins user interface and user experience. Join us!
See this page for more information about contributing to the Jenkins codebase. If you want to know more, join us in the Jenkins User Experience SIG channels.
References
You can find more information about the Hackfest here:
On the closing day of Spark + AI Summit, Databricks CEO Ali Ghodsi recognized three exceptional data teams for how they came together to solve a tough problem– delivering impact, innovation, and helping to make the world a better place.
These are the inaugural Databricks Data Team Awards, and we were blown away by the submissions and the finalists, representing a wide variety of data science use cases spanning multiple industries. Across the board, they showcased how a unified analytics platform like Databricks can help bring together the diverse talents of data engineers, data scientists and data analysts to focus their ideas, skills and energy toward accomplishing amazing things.
Here are, the 2020 Databricks Data Team Awards winners:
Data Team for Good Award: Aetion
Aetion’s data team is working on a high-impact use case related to the COVID-19 crisis. Specifically, Aetion has partnered with HeathVerity to use Databricks to ingest and process data from multiple inputs into real-time data sets to be used to analyze COVID-19 interventions and to study the pandemic’s impact on health care utilization. Their integrated solution includes a Real-Time Evidence Platform that enables biopharma, regulators, and public health officials to generate evidence on the usage, safety, and effectiveness of prospective treatments for COVID-19 and to continuously update and expand this evidence over time. This new, high-priority use case for Aetion has already produced a social impact—it will be employed in the company’s new research collaboration with the U.S. FDA, which will support the agency’s understanding of and response to the pandemic.
Accepting the award on behalf of the team at Aetion was John Turek, CTO.
Runners-up: Alignment Healthcare, Medical University of South Carolina
Data Team Impact Award: Disney+
Disney+ surpassed 50 million paid subscribers in just five months and is available in more than a dozen countries around the world. Data is essential to understanding customer growth and to improve the overall customer experience for any streaming business. Disney+ uses Databricks as a core component of its data lake, and using the Databricks Delta Lake, it has been able to build streaming and batch data pipelines supporting petabytes of data. The platform is enabling teams to collaborate on ideas, explore data, and apply machine learning across the entire customer journey, to foster growth in its subscriber base.
Accepting the award on behalf of his team at Disney+ was Tom LeRoux, VP of Engineering.
Runners-up: Unilever, YipitData
Data Team Innovation Award: Goldman Sachs
To better support its clients, the Marcus by Goldman Sachs data team continues to innovate its offerings and, in this instance, leveraged Databricks to build a next generation big data analytics platform that addresses diverse use cases, spanning from credit risk assessment, to fraud detection to marketing analytics and compliance. The unified data team not only built a robust and reliable infrastructure but also activated and empowered hundreds of analysts and developers in a short number of months.
Accepting the award for the Marcus by Goldman Sachs team was Executive Director Karthik Ravindra.
Runners-up: Comcast, Zalando
Data Teams Unite!
Congratulations to the Data Team Award winners for their exceptional achievements!
We look forward to seeing data teams worldwide leverage the power of Databricks to unite. And we will continue to celebrate them for using data and artificial intelligence to help to solve the world’s toughest problems.
Databricks is pleased to announce the release of Databricks Runtime 7.0 for Machine Learning (Runtime 7.0 ML) which provides preconfigured GPU-aware scheduling and adds enhanced deep learning capabilities for training and inference workloads.
Preconfigured GPU-aware scheduling
Project Hydrogen is a major Apache Spark™ initiative to bring state-of-the-art artificial intelligence (AI) and Big Data solutions together. Its last major project, accelerator-aware scheduling, is made available in Apache Spark 3.0 by a collaboration among developers at Databricks, NVIDIA, and other community members.
In Runtime 7.0 ML, Databricks preconfigures GPU-aware scheduling for you on GPU clusters. The default configuration uses one GPU per task, which is ideal for distributed inference workloads and distributed training if you use all GPU nodes. If you want to do distributed training on a subset of nodes, Databricks recommends setting spark.task.resource.gpu.amount to the number of GPUs per worker node in the cluster Spark configuration, to help reduce communication overhead during distributed training.
For PySpark tasks, Databricks automatically remaps assigned GPU(s) to indices 0, 1, …. Under the default configuration that uses one GPU per task, your code can simply use the default GPU without checking which GPU is assigned to the task. This is ideal for distributed inference. See our model inference examples (AWS | Azure).
For the distributed training tasks with HorovodRunner (AWS | Azure), users do not need to do any modifications when migrating their training code from older versions to the new release.
Simplified data conversion to Deep Learning frameworks
Databricks Runtime 7.0 ML includes Petastorm 0.9.2 to simplify data conversion from Spark DataFrame to TensorFlow and PyTorch. Databricks contributed a new Spark Dataset Converter API to Petastorm to convert a Spark DataFrame to a TensorFlow Dataset or a PyTorch DataLoader. For more details, check out the blog post for Petastorm in Databricks and our user guide (AWS | Azure).
NVIDIA TensorRT for high-performance inference
Databricks Runtime 7.0 ML now also includes NVIDIA TensorRT. TensorRT is an SDK that focuses on optimizing pre-trained networks to run efficiently for inferencing especially with GPUs. For example, you can optimize performance of the pre-trained model by using reduced-precision (e.g. FP16 instead of FP32) for production deployments of deep learning inference applications. For example, for a pre-trained TensorFlow model, the model can be optimized with the following python snippet
After a deep learning model is optimized with TensorRT, it can be used for inference just as unoptimized models. See our example notebook for using TensorRT with TensorFlow (AWS| Azure).
To achieve the best performance and cost for reduced-precision inference workloads, we highly recommend using TensorRT with the newly supported G4 instance types on AWS.
Support for TensorFlow 2
Runtime 7.0 ML includes TensorFlow 2.2. TensorFlow 2 contains many new features as well as major breaking changes. If you are migrating from TensorFlow 1.x, Databricks recommends reading TensorFlow’s official migration guide and Effective TensorFlow 2. If you have to stay with TensorFlow 1.x, you can enable %pip and downgrade TensorFlow, e.g., to 1.15.3, using the following command in a Python notebook:
%pip install tensorflow==1.15.3
Read our blog post and user guide (AWS | Azure) to learn how to enable and use %pip and %conda on Runtime 7.0 ML.
Resources
Databricks Runtime 7.0 ML release notes (AWS | Azure)
The Zero Trust Model of information security simplifies how information security is conceptualized by assuming there are no longer “trusted” interfaces, applications, traffic, networks, or users. It takes the old model— “trust but verify”—and inverts it, because recent breaches have proven that when an organization trusts, it doesn’t verify [6].
This model requires that the following rules be followed [6]:
All resources must be accessed in a secure manner.
Access control must be on a need-to-know basis and strictly enforced.
Systems must verify and never trust.
All traffic must be inspected, logged, and reviewed.
Systems must be designed from the inside out instead of the outside in.
The zero-trust model has three key concepts:
Ensure all resources are accessed securely regardless of location.
Adopt a least privilege strategy and strictly enforce access control.
Inspect and log all traffic.
“Outside-In” to “Inside-Out” Attacks
According to a Forrester Research report, information security professionals should readjust some widely held views on how to combat cyber risks. Security professionals emphasize strengthening the network perimeter, the report states, but evolving threats—such as increasing misuse of employee passwords and targeted attacks—mean executives need to start buffering internal networks. In the zero-trust security model, companies should also analyze employee access and internal network traffic. One major recommendation of ...
With the adoption of artificial intelligence in many businesses, testing practices are on the verge of revolution, especially in terms of test case management, test design, and test case execution. Artificial intelligence is often defined as the science and engineering of creating intelligent machines that can display intellectual behavior. The integration of artificial intelligence in software development and testing practices improves the accuracy and quality of the end product while reducing the efforts and the invested time.
When it comes to test case management, the AI-based solutions have the ability to create test cases, select the most adequate case to execute, and also recommend the best testing strategy by taking into account all variables and scenarios. By assimilating proficient test case management tools and AI-based solutions, the teams are able to analyze the results and derive actionable insights for future use as well.
Machine Learning Application in Test Case Management
Test cases are a critical part of the software testing, which determines the scope and the nature of the test. It is also important to note that the quality and impact of the overall testing process is highly contingent on the kind of test cases that are generated and used during testing.
Researchers at Vanderbilt University Medical Center are using a novel, data-driven “target trial” framework to investigate the efficacy and safety of medicines in pregnant women, who are underrepresented in randomized controlled trials (RCTs). The approach leverages observational data in electronic health records (EHRs) to spot connections between real-world drug exposures during pregnancy and adverse outcomes in the women’s offspring—an exercise that can be expedited with commonly used AI machine learning models like logistic regression.
So says Vanderbilt undergraduate student Anup Challa, founding director of the investigative collaboration MADRE (Modeling Adverse Drug Reactions in Embryos). The group works in the emerging field of PregOMICS that applies systems biology and bioinformatics to study the efficacy and safety of drugs in treating a rising tide of obstetrical diseases. Partnering institutions are Northwestern University, the National Institutes of Health, and the Harvard T.H. Chan School of Public Health.
The concept of target trials was first mentioned in epidemiology literature a decade ago, says Challa, and is only starting to gain traction. “Target trials really hinge on retrospective analysis of existing data using machine learning methods or other kinds of inferential statistics.”
Anup Challa, founding director, MADRE (Modeling Adverse Drug Reactions in Embryos)
A study coming out of Vanderbilt a few years ago looked at the effects of pregnant patients’ genomics on outcomes in their neonates and found harmful single-nucleotide mutations on key maternal genes that mimicked patients taking inhibitory drugs, says Challa. Specifically, the research team conducted a target trial to learn that these mutations on the gene PCSK9, which controls cholesterol levels, led mothers to deliver babies with spina bifida.
That was a signal that mothers ought not to be taking PCSK9 inhibitors, Challa continues, which are “becoming of increasing interest to physicians for treating hypercholesterolemia.” It also meant common genetic variants could serve as a proxy for drug exposures in target trials when insufficient prescription data exist in pregnant people’s records.
A probability value generated by a machine learning algorithm would not be “sufficiently indicative” of a drug safety signal to warrant immediate interrogation in humans, says David Aronoff, M.D., director of the division of infectious diseases at the Vanderbilt University Medical Center. But, as he and his MADRE colleagues argued in a recent paper published in Nature Medicine (DOI: 10.1038/s41591-020-0925-1), target trials are a viable and potentially more definitive alternative to fetal safety than animal models or cellular response to a drug in a dish.
The ultimate goal with target trials is to simulate the level of safety and efficacy testing done in RCTs with non-pregnant populations as a matter of health equity for people who for ethical or logistical reasons can’t be enrolled, says Challa. But where they fit into the regulatory framework for drugs has yet to be defined, or even explored.
Next Step: Tissue Modeling
Aronoff thinks of target trials as “reverse engineering” the normal drug development process, which typically starts in a petri dish on the bench then advances to animal models and finally clinical trials outside the pregnant population that (if all goes well) leads to an indication for use. “We’re trying to take existing, real-world data about the use of those drugs in pregnancy to identify [safety] signals… some sort of problem in the development of the fetus in utero that ends up showing itself either during pregnancy or postpartum in the offspring. If there is a mechanistic basis for that, then we can now go backwards to the bench and try to understand whether there is a causal relationship.”
David Aronoff, M.D., director, division of infectious diseases, Vanderbilt University Medical Center
Organ-on-a-chip technologies and other advances in tissue modeling can be particularly good at recapitulating drug exposure information, “particularly in the context of what is happening in the pregnant uterus,” says Aronoff. His MADRE colleague Ethan Lippmann, Ph.D., in Vanderbilt’s department of chemical and biomolecular engineering, has been building three-dimensional models of brain development that could be used as a platform for testing the teratogenic effects of drugs (or metabolites of those drugs) on neural development and neural outcomes like seizure disorders or microcephaly.
Aronoff, who is also a professor of obstetrics and gynecology at Vanderbilt, is keenly interested in seeing three-dimensional organotypic models of the placenta exposed to various drugs, metabolites and toxins of interest—and serially to other organ models that might include the brain, heart and musculoskeletal system. The different models could be viewed as “cartridges” that get plugged in based on signals seen in the machine learning study.
“We’re trying to look at organ development and organ function in this better, more innovative context,” says Aronoff, which would add to what is learned from target trials.
The potential of target trials is both about discovering and investigating drug safety, says Aronoff. “Most drugs have never been clinically tried in a randomized, placebo-controlled way in pregnancy and, even if they have been, it’s uncertain that anyone was paying close attention to outcomes not only for the fetus but in early childhood and [beyond]. But when you have electronic health records that couple mothers and their exposures with their offspring sometimes even years later, you have the power to discover for the first time an association that no one knew about.”
That first level of discovery—e.g., a higher level of prevalence of schizophrenia or autism or asthma in childhood due to exposure to a drug in the womb—prompts questions about whether the association has a mechanistic basis that may be revealing of fundamental aspects of human development, he notes.
Indeed, it should be possible to use target trials as a first step in identifying whether diseases that occur later in life are linked to an earlier stimulus or cause, adds Challa. The story of an individual’s health is influenced by factors not immediately visible, including exposures in utero that can lead to lifelong disease.
EHRs could provide researchers with the ability to evaluate people’s health from the time they were in their mother’s uterus until late in life, so they can start to think from a “systems perspective,” says Challa. When tapped by target trials, they greatly enlarge the information available to guide therapeutic choices and inform drug safety.
QSAR Technique
Many databases and patient registries exist for reproductive toxicology and the reporting of significant adverse events. But the information isn’t available in a form that’s easily manipulated by machine learning models, says Challa, making it challenging to arrive at statistically rigorous results.
The problem extends to Food and Drug Administration and National Institutes of Health datasets used in a recent study appearing in Reproductive Toxicology. “What we found and continue to find is that the data out there is not at the level it should be” for informing prescribing behavior at the point of care for pregnant women and their developing fetuses, Challa says.
The study was attempting to identify chemical features of a drug that would be predictive of its teratogenic potential and could be fed into a machine learning model to formalize those associations, he explains. Specifically, researchers looked at whether or not adverse outcomes have an “inherent structural rationale” and, if so, if a meta-structural analysis might be performed to identify known pharmacological variables (e.g., absorption, distribution, metabolism, and excretion profile) that may be the culprits. They also accessed real-world laboratory data to look for chemical structures associated with markers of disease in human tissue samples.
Recognition of the conflicting nature of adverse events data within patient registries was a key takeaway of the study, says Challa, and gave researchers “even more impetus” to focus on EHRs as a data source. But it also gave the team some structural information predictive of an adverse outcome that they can now use to cross-validate results produced by their target trial framework.
The paper highlighted a novel application of machine learning, the quantitative structure activity relationship (QSAR), to learn about the structures of drugs and their pharmacological behaviors that are associated with teratogenicity. QSAR should also be able to make similar predictions for any new compound, says Aronoff. “It’s a separate way [than EHR mining] of interrogating drug safety to look for associations.”
The two techniques are related in that any unwanted drug effects in a fetus or offspring that are uncovered in medication-wide association studies could be plugged into QSAR, Aronoff says. Perhaps something already known about the drug’s structure could point to a causal relationship, a hypothesis which could then get tested more directly in tissue models.
Aronoff’s hypothetical example is an antidepressant drug that gets newly associated with an adverse pregnancy outcome. “Can we keep its antidepressant activity but enhance its safety by targeting the structure that is actually the bad actor?” If so, he says, medicinal chemistry stands to gain some ground.
Linked Patient Records
Another limitation of mining the databases where adverse events are being reported is that “some subtle, infrequent and unexpected relationships” invariably get missed, says Aronoff. Women may be on medications chronically when they give birth to a child with a teratogenic problem or later health problem and “there may be no awareness that those things are related.” It’s unreasonable to expect anyone to make the mental connection when years can separate the drug exposure and unwanted outcome.
Target trials use the power of machine learning to interrogate hundreds of thousands, if not millions, of linked patient records to find the “needles in the haystack,” Aronoff adds. “In some respects, that can be much more sensitive than relying on individual people to report some association where there may need to be an incredibly strong signal or very horrible outcomes that are chronologically associated with the exposure.”
Available adverse exposure reporting information is also mostly freeform text, making it difficult to extract for use in target trial models, says Challa. EHRs, in contrast, are much more structured and minable documents.
Vanderbilt has taken a leadership position in creating meaningful databases out of EHR information, Challa says, including the use of natural language processing to put text fields in a machine-readable format. Its BioVU DNA repository, for instance, consists of high-quality, up-to-date genomics information linked to de-identified medical records and is routinely updated and maintained by a team of on-campus IT experts. Another repository is Vanderbilt’s longstanding Research Derivative, a database of identified health records and related data drawn from Vanderbilt University Medical Center’s clinical systems and restructured for research.
Large databases of linked health records, available mainly at institutions with similar patient volume and health IT infrastructure as Vanderbilt (whose clinical databanks contain EHR information for more than 2 million patients), are what make target trials feasible, says Challa. “It is often unethical to create linkages across clinical datasets that don’t already have it.”
Ethical Approach
The proposed target trials framework will robustly input several medication exposures of interest from pregnant patients and try to associate them with a battery of developmental outcomes from the EHRs of their children, says Challa. In contrast, clinical trials typically test the potency and safety of one drug for a single disease or cluster of similar diseases.
By providing a basis for causal inference, target trials are “the only ethical way to gather human drug exposure data for pregnant people on a significant scale and across all classes of drugs,” he and his colleagues argue in the Nature Medicine paper.
Within a few years, MADRE researchers hope to be inputting drug lists into a reproducible set of machine learning algorithms and statistical methods and outputting associations to several serious neurodevelopmental diseases, Challa says. Future plans also include taking positive drug-disease associations in pediatric patients and extrapolating the impact of early exposures to their later life course.
“As I like to say to my friends who are physicians and have specialty areas,” Aronoff says, “many people suffer from the diseases they care about, but every human being has experienced childbirth. We have to get that right.”
While pregnant people should be enrolled in RCTs of drugs and vaccines, Aronoff adds, “the reality is that [pregnancy] is always going to be a barrier. Target trials are a way forward.”
By Berge Ayvazian, Senior Analyst and Consultant at Wireless 20/20
The major US mobile operators are all deploying their 5G networks in 2020, and each one claims that AI and machine learning will help them proactively manage the costs of deploying and maintaining new 5G networks. AT&T recently outlined the company’s blueprint for leveraging artificial intelligence and machine learning (ML) to maximize the return on its 5G network investment. AT&T’s Mazin Gilbert sees a “perfect marriage” of AI, ML and software defined networking (SDN) to help enable the speeds and low latency of 5G.
AT&T is using AI and ML to map its existing cell towers, fiber lines, and other transmitters that today, to build its 5G infrastructure and to pinpoint the best location for 5G build outs in the future. AT&T has more than 75,000 macro cells in its network and is using AI to guide plans for deploying hundreds of thousands of additional small cells and picocells. If AI detects a cell site isn’t functioning properly, it will signal another tower to pick up the slack.
AT&T is using AI to load balance traffic such as video on its network, and the company is using machine learning to detect congestion on small cells on 5G networks before service degrades. If one area is experiencing a high volume of usage, AI will trigger lower-use cell sites to ensure that speed isn’t compromised. AT&T is also leveraging AI and ML to improve efforts in forecasting and capacity planning with the dispatch field services that help customers every day. And AI is being used to optimize schedules for technicians, to get as many jobs done during the workday as possible by minimizing drive time between jobs while maximizing jobs completed per technician.
AT&T is building its AI platform to scale from the core to the edge network and is putting more intelligence into its mobile edge compute (MEC) at the customer edge and into its radio access network (RAN). By putting intelligence closer to the edge, AT&T is starting to load balance traffic across these small cells and move traffic around when needed. AI will also help enable SLAs from networking slicing offerings to AT&T’s customers. AI is also the key ingredient for implementing numerous new projects and platforms for AT&T, which is using AI to manage its third-party cloud arrangements, such as with Microsoft, and in its internal cloud and hybrid clouds. In addition, AT&T is using AI to define policies that are currently set by systems and employees. AI and the data analytics tell AT&T if any of the policies have conflicts prior to defining them.
AI-driven Automation Transforms 5G Network Reliability and Wireless Field Service
Verizon recently confirmed that its plans for its 5G rollout across the US are ahead of schedule. Verizon EVP and CTO Kyle Malady has reported that despite the coronavirus pandemic, the largest US wireless operator is successfully moving the technology forward with its 5G and intelligent edge network. Verizon is also using its AI-enabled Verizon Connect intelligent fleet and field service management platform to closely monitor 5G wireless network usage in the areas most impacting customers and communities during the COVID-19 pandemic. Verizon Wireless uses this platform to prioritize network demand, track assets and vehicles, dispatch employees and monitor work being performed for mission-critical customers including hospitals, first responders and government agencies. Reveal Field from Verizon Connect integrates proactive maintenance, intelligent scheduling and dispatching to improve first-time fix rates and reduce mean time to resolution.
AT&T and Verizon are not the only wireless operators focusing on the synergy between 5G and AI. Orange recently appointed former Orange Belgium CEO, Michaël Trabbia, as chief technology and innovation officer with a mandate to leverage 5G, AI, cloud edge technologies and NFV (network function virtualization) under the French carrier’s Engage2025 strategic plan. Orange recognizes the need to detect, accelerate and shorten reaction and decision times to confront with confidence the profound changes brought about by the global coronavirus epidemic. There are many uncertainties but also real opportunities for the Orange Post-Covid Strategy; the new CTO will drive AI and 5G innovation to seize these possible opportunities and accelerate digital transformation.
Michaël Trabbia, CEO, Orange Belgium
T-Mobile, AI and Enriching the Customer Experience
T-Mobile has long prided itself as a disruptor in the world of wireless communications, always thinking creatively about the relationship it wants to have with its consumers. That includes T-Mobile’s approach to using AI to enhance customer service. The Uncarrier believes the predictive capabilities of AI and machine learning creates an opportunity to serve customers better and faster, benefiting not just the company and its service agents but also enriching the customer service experience. T-Mobile could have used these advancements in AI-based proactive maintenance and intelligent network management to help address a recent emergency. The carrier had to resolve a 13-hour intermittent network outage that impacted customer ability to make calls and send text messages throughout the US.
After discounting rumors of widespread DDoS attack, Neville Ray, T-Mobile’s president of technology acknowledged the network outage has been linked to increased IP traffic that created significant capacity issues in the network. The trigger event was determined to be the failure of a leased fiber circuit from a third-party provider in the Southeast. The resulting overload resulted in an IP traffic storm that spread from the Southeast to create significant capacity issues across the IMS (IP multimedia Subsystem) core network that supports VoLTE calls. Ray reported that hundreds of engineers worked tirelessly alongside vendors and partners throughout the day to understand the root causes and resolve the issue. FCC Chairman Ajit Pai has called the T-Mobile outage “unacceptable” and added that the Commission would launch an investigation and demand answers regarding the network configuration and traffic related problems that created significant capacity issues in the mobile core network throughout the day. Now that the nationwide network outage is over, perhaps T-Mobile could leverage AI and machine learning as it works with vendors to “add permanent additional safeguards” that would prevent such an issue from happening again.
Neville Ray, President of Technology, T-Mobile
AI and machine learning are helping 5G wireless carriers and IoT service providers to drive efficiency across their organizations, from the back office to the field. Zinier recently raised $90 million in venture capital to accelerate its effort to integrate AI technology to help automate field service management. The company is integrating AI and automation to create the next generation of intelligent field service automation. “Touchless service delivery” aims to drive predictive maintenance, increase network uptime and reduce costs. Zinier believes that AI-driven automation can help mobile operators streamline field service processes ahead of 5G deployments. By analyzing real-time data against historical trends, leading wireless operators can leverage AI to create predictive insights and optimize intelligent field service operations. Zinier’s AI-driven automation platform can help wireless field service organizations install and maintain a rapidly increasing number of job sites for new 5G wireless networks.
AI, 5G and Digital Transformation
AI has transformational power for any company, and mobile operators know it will digitally disrupt every industry. Mobile operators are integrating AI-enabled deep automation with their 5G networks, unleashing new business opportunities by accelerating digital transformation. The synergy between AI and 5G is likely to lead to dramatic breakthroughs that will have a profound impact on a wide range of industries. The convergence of 5G and AI holds tremendous promise to revolutionize healthcare, education, business, agriculture, IoT applications and waves of innovation that have not even been imagined. Verizon currently has seven 5G labs and recently created a new virtual lab to speed development of 5G solutions and applications for consumers, businesses, and government agencies. Verizon recently launched the first laptop for its 5G Ultra Wideband Connected Device Plan. The new Lenovo Flex 5G laptop will also connect to WiFi, Verizon’s 4G LTE and the new low-band 5G network scheduled to go live later this year.
Having completed its merger with Sprint, T-Mobile recently announced the rebranding of the Sprint Accelerator program. The T-Mobile Accelerator will continue the founding principles and mission of the original program to drive development in AI, drones, robotics, autonomous vehicles and more on the Un-carrier’s nationwide 5G network. T-Mobile also unveiled six exciting companies handpicked to participate in this year’s T-Mobile Accelerator and work directly with T-Mobile leaders, other industry experts and mentors to develop and commercialize the next disruptive emerging products, applications and solutions made possible by T-Mobile’s nationwide 5G network.
Wireless Broadband Connectivity and the New Online World
We are all living in a new online world, as social distancing forces many of us to work, communicate and connect in new ways. In the US alone, 316 million Americans have been urged to stay indoors and, when possible, work from home. As communities around the world adapt to a world with COVID-19, broadband connectivity and access have become more critical to our lives and livelihoods than ever before. Broadband already powers much of our modern lives, but COVID-19 has acted as an accelerant that has driven many essential activities online. All learning, many healthcare services, retail commerce, most workplaces and daily interactions online require a high-speed broadband connection to the internet. The FCC’s 2020 Broadband Deployment Report estimated that more than 21 million Americans lacked high-speed broadband access at year end 2019. A new study from BroadbandNow estimates the actual number of people lacking access to broadband in the US could be twice as high – closer to 42 million. The primary reason for the disparity between these estimates is a flaw in FCC Form 477 self-reporting, where if an ISP reports offering broadband service to at least one household in a census block, that entire block counts as being covered by that provider. Manually checking internet availability for each address has resulted in a more accurate estimation of broadband connections.
Americans living in remote and sparsely populated rural areas risk falling farther behind without broadband access to this online world. But ISP self-reporting and manual cross-checking do not seem to be the most effective ways to collect this data, to identify gaps in broadband performance and to ultimately expand broadband availability. The FCC’s Measuring Broadband America (MBA) program offers rigorous broadband performance testing for the largest wireline broadband providers that serve well over 80% of the U.S. consumer market. The MBA program also uses a Speed Test app, a smartphone-based technology to collect anonymized broadband performance data from volunteers participating in the collaborative, crowdsourcing initiative. This ongoing nationwide performance study of broadband service is designed to improve the availability of information for consumers about their broadband service.
Wireless 20/20 believes that AI and big data analytics should be used to extract more accurate, precise and actionable information from the FCC’s Form 477 reporting and Measuring Broadband America (MBA) data. These new metrics should be used to drive the FCC’s newly adopted Rural Digital Opportunity Fund (RDOF) rules for $20.4 billion Auction 904 rural broadband funding and upcoming spectrum auctions to bridge the digital divide.
The next major disruptive opportunity will come from 5G and AI in changing the way we connect and power our communities. Given the challenges we are all facing with the COVID-19 pandemic, 5G wireless broadband and AI could be used to enable Tele-health networks, distance learning and advanced IoT networks to power the Fourth Industrial Revolution where working from home becomes the new normal.
Berge Ayvazian leads an integrated research and consulting practice at Wireless 20/20 on 4G/5G Networks and Mobile Internet Evolution. This report is based on a recent presentation he was invited to make for theFCC’s Artificial Intelligence Working Group (AIWG) focusing on the Synergy Between AI, 5G and IoT. He was asked for his expert opinion on what is real, what is hype, and his opinion of the maturity of AI technology. Learn more atWireless 20/20.
AI techniques are being applied by researchers aiming to extend the life and monitor the health of batteries, with the aim of powering the next generation of electric vehicles and consumer electronics.
Researchers at Cambridge and Newcastle Universities have designed a machine learning method that can predict battery health with ten times the accuracy of the current industry standard, according to an account in ScienceDaily. The promise is to develop safer and more reliable batteries.
In a new way to monitor batteries, the researchers sent electrical pulses into them and monitored the response. The measurements were then processed by a machine learning algorithm to enable a prediction of the battery’s health and useful life. The method is non-invasive and can be added on to any battery system.
The inability to predict the remaining useful charge in lithium-ion batteries is a limitation to the adoption of electric vehicles, and annoyance to mobile phone users. Current methods for predicting battery health are based on tracking the current and voltage during battery charging and discharging. The new methods capture more about what is happening inside the battery and can better detect subtle changes.
“Safety and reliability are the most important design criteria as we develop batteries that can pack a lot of energy in a small space,” stated Dr. Alpha Lee from Cambridge’s Cavendish Laboratory, who co-led the research. “By improving the software that monitors charging and discharging, and using data-driven software to control the charging process, I believe we can power a big improvement in battery performance.”
Dr. Alpha Lee, Cavendish Laboratory, Cambridge University
The researchers performed over 20,000 experimental measurements to train the model in how to spot signs of battery aging. The model learns how to distinguish important signals from irrelevant noise. The model learns which electrical signals are most correlated with aging, which then allows the researchers to design specific experiments to probe more deeply why batteries degrade.
“Machine learning complements and augments physical understanding,” stated co-author Dr Yunwei Zhang, also from the Cavendish Laboratory, in .”The interpretable signals identified by our machine learning model are a starting point for future theoretical and experimental studies.”
Department of Energy Researchers Using AI Computer Vision Techniques
Researchers at the Department of Energy’s SLAC National Accelerator Laboratory are using AI computer vision techniques to study battery life. The scientists are combining machine learning algorithms with X-ray tomography data to produce a detailed picture of degradation in one battery component, the cathode, according to an account in SciTechDaily. The referenced study was published in Nature Communications.
Dr. Yunwei Zhang, Cavendish Laboratory, Cambridge University
For cathodes made of nickel-manganese-cobalt (NMC) particles are held together by a conductive carbon matrix. Researchers have speculated that a cause of battery performance decline could be particles breaking away from that matrix. The team had access to advanced capabilities at SLAC’s Stanford Synchrotron Radiation Lightsource (SSRL), a unit of the Department of Energy operated by Stanford University, and the European Synchrotron Radiation Facility (ESRF), a European collaboration for the advancement of X-rays, based in Grenoble, France. The goal was to build a picture of how NMC particles break apart and away from the matrix, and how that relates to battery performance loss.
The team turned to computer vision with AI capability to help conduct the research. They needed a machine learning model to train the data in how to recognize different types of particles, so they could develop a three-dimensional picture of how NMC particles, large or small, break away from the cathode.
The authors encouraged more research into battery health. “Our findings highlight the importance of precisely quantifying the evolving nature of the battery electrode’s microstructure with statistical confidence, which is a key to maximize the utility of active particles towards higher battery capacity,” the authors stated.
(Citation: Jiang, Z., Li, J., Yang, Y. et al. Machine-learning-revealed statistics of the particle-carbon/binder detachment in lithium-ion battery cathodes. Nat Commun 11, 2310 (2020). https://doi.org/10.1038/s41467-020-16233-5)
(For an account of how researchers from Stanford University, MIT and the Toyota Research Institute are studying radical reductions in electric-vehicle charging times, see AI Trends.).