Analytics tools are one of the most crucial parts of business success in the twenty-first century. While it's not as magical as a crystal ball, analytics can provide in-depth knowledge about the state of a company and help it predict with some certainty what will happen. Grand View Research explains that predictive analytics has the potential to rapidly grow up to 2025. The reason why predictive analytics is so successful is by spotting trends and patterns within massive swathes of data. In the case of distributors, predictive analytics can change how they approach their goals.Commercial Planning is EasierIt's tough to figure out what works and what doesn't when it comes to business. Between mergers, acquisitions, and the company's growth, the dynamic nature of a business is hard to plan for. Utilizing predictive analytics can offer some support for commercial planning for companies. By experimenting with different starting values, the company can determine what is the most optimal method forward. Ideas such as linear programming to maximize growth and profit immediately come to mind as good examples of how predictive analytics can help a business. With accurate data, predictive analytics models can be eerily accurate.Fraud is Easier to DetectTypical predictive analytics ...
Read More on Datafloq
Sunday, 31 May 2020
Ravi Shankar Prasad launches AI portal; programme for youth to build the skills
The platform will act as a one-stop digital platform for AI-related developments in India, sharing of resources details of startups, investment funds in AI, companies, and educational institutions related to AI in India.
Friday, 29 May 2020
China's Didi Chuxing raises over $500 million for autonomous driving unit
The round was led by SoftBank Vision Fund 2 and marks the first time Didi's autonomous driving business has brought in external funding
Breaking The Coronavirus Jinx With Virtual Call Center Solutions
The impact of COVID-19 has been immense, nothing like anyone could have imagined. To make things worse, things don’t seem to be getting back on track anytime in the near future. It would be right to think that work from home is going to be a norm, not for weeks, but months or even years. Seeing the silver lining, the human race has shown great resilience and adaptability for coping with the virus. Companies of all sizes have switched to the remote working models and both businesses and employees are somewhat comfortable with the concept. Globally, companies are gradually learning to maintain productivity while working in this new model through a crisis like a world has never faced before. At the same time, they are going the extra mile to empower employees with the right tools to facilitate work from home. Virtual call center solutions come ahead as one of the most significant remote working tools that are serving as a lifeline for businesses in the pandemic-hit era. From ensuring top-notch productivity to easing remote working and facilitating exceptional customer support, there are many ways in which virtual call center software is empowering businesses of all sizes.Let us explain how ...
Read More on Datafloq
Read More on Datafloq
Tech walks the ramp in fashion makeover
Covid-19 pandemic forcing brands to pivot to remote shopping, 3D body mapping, virtual trials
Why Small Business Should Embrace AI
Small business owners are facing a myriad of serious challenges these days. An economic shutdown has left them bereft of customers while their corporate counterparts keep growing, and an inability to adapt to the latest technological trends continues to threaten their future profitability. Nevertheless, many small business owners are refusing to allow their fledgling commercial empires to crumble easily. Dedicated entrepreneurs are embracing novel marketing methods and exhilarating new technologies like artificial intelligence to remain effective and profitable in the modern marketplace.You may think AI is only accessible to major corporations, but the truth of the matter is that it’s becoming easier and easier for everyday entrepreneurs to use by the month. Here’s a breakdown of why small businesses should embrace AI sooner rather than later.Companies are already leveraging AIPerhaps the most compelling reason that your small business should consider embracing the power of artificial intelligence is that other companies are already leveraging it. Massive tech companies like IBM and Alphabet have been making use of AI for years now, but it would be a serious mistake to think that AI exclusively resides within the corporate domain. As a matter of fact, the past couple of years have introduced a ...
Read More on Datafloq
Read More on Datafloq
AI Autonomous Cars And The Problem Of Where To Drop Off Riders

By Lance Eliot, the AI Trends Insider
Determining where to best drop-off a passenger can be a problematic issue.
It seems relatively common and downright unnerving that oftentimes a ridesharing service or taxi unceremoniously opts to drop you off at a spot that is poorly chosen and raft with complications.
I remember one time, while in New York City, a cab driver was taking me to my hotel after my having arrived past midnight at the airport, and for reasons I’ll never know he opted to drop me about a block away from the hotel, doing so at a darkened corner, marked with graffiti, and looking quite like a warzone.
I walked nearly a city block at nighttime, in an area that I later discovered was infamous for being dangerous, including muggings and other unsavory acts.
In one sense, when we are dropped off from a ridesharing service or its equivalent, we often tend to assume that the driver has identified a suitable place to do the drop-off.
Presumably, we expect as a minimum:
· The drop-off is near to the desired destination
· The drop-off should be relatively easy to get out of the vehicle at the drop-off spot
· The drop-off should be in a safe position to get out of the vehicle without harm
· And it is a vital part of the journey and counts as much as the initial pick-up and the drive itself.
In my experience, the drop-off often seems to be a time for the driver to get rid of a passenger and in fact the driver’s mindset is often on where their next fare will be, since they’ve now exhausted the value of the existing passenger and are seeking more revenue by thinking about their next passenger.
Of course, you can even undermine yourself when it comes to doing a drop-off.
The other day, it was reported in the news that a woman got out of her car on the 405 freeway in Los Angeles when her car had stalled, and regrettably, horrifically, another car rammed into her and her stalled vehicle. A cascading series of car crashes then occurred, closing down much of the freeway in that area and backing up traffic for miles.
In some cases, when driving a car ourselves, we make judgements about when to get out of the vehicle, and in other cases such as ridesharing or taking a taxi, we are having someone else make a judgement for us.
In the case of a ridesharing or taxi driver, I eventually figured out that as the customer I need to double-check the drop-off, along with requesting an alternative spot to be dropped off if the circumstances seem to warrant it. You usually assume that the local driver you are relying on has a better sense as to what is suitable for a drop-off, but the driver might not be thinking about the conditions you face and instead could be concentrating on other matters entirely.
Here’s a question for you, how will AI-based true self-driving driverless autonomous cars know where to drop-off human passengers?
This is actually a quite puzzling problem that though not yet seemingly very high on the priority list of AI developers for autonomous cars, ultimately the drop-off matter will rear its problematic head as something needing to be solved.
For my overall framework about autonomous cars, see this link: https://aitrends.com/ai-insider/framework-ai-self-driving-driverless-cars-big-picture/
For why achieving a true self-driving car is like a moonshot, see my explanation here: https://aitrends.com/ai-insider/self-driving-car-mother-ai-projects-moonshot/
For my indication about edge or corner cases in AI autonomous cars, see this link: https://aitrends.com/ai-insider/edge-problems-core-true-self-driving-cars-achieving-last-mile/
For dangers that await pedestrians and how AI self-driving car should respond, see my discussion here: https://aitrends.com/ai-insider/avoiding-pedestrian-roadkill-self-driving-cars/
AI Issues Of Choosing Drop-off Points
The simplistic view of how the AI should drop you off consists of the AI system merely stopping at the exact location of where you’ve requested to go, as though it is merely a mathematically specified latitude and longitude, and then it is up to you to get out of the self-driving car.
This might mean that the autonomous car is double-parked, though if this is an illegal traffic act then it goes against the belief that self-driving cars should not be breaking the law.
I’ve spoken and written extensively that it is a falsehood to think that autonomous cars will always strictly obey all traffic laws, since there are many situations in which we as humans bend or at times violate the strict letter of the traffic laws, doing so because of the necessity of the moment or even at times are allowed to do so.
In any case, my point is that the AI system in this simplistic perspective is not doing what we would overall hope or expect a human driver to do when identifying a drop-off spot, which as I mentioned earlier should have these kinds of characteristics:
· Close to the desired destination
· Stopping at a spot that allows for getting out of the car
· Ensuring the safety of the disembarking passengers
· Ensuring the safety of the car in its stopped posture
· Not marring the traffic during its stop
· Etc.
Imagine for a moment what the AI would need to do to derive a drop-off spot based on those kinds of salient criteria.
The sensors of the self-driving car, such as the cameras, radar, ultrasonic, LIDAR, and other devices would need to be able to collect data in real-time about the surroundings of the destination, once the self-driving car has gotten near to that point, and then the AI needs to figure out where to bring the car to a halt and allow for the disembarking of the passengers. The AI needs to assess what is close to the destination, what might be an unsafe spot to stop, what is the status of traffic that’s behind the driverless car, and so on.
Let’s also toss other variables into the mix.
Suppose it is nighttime, does the drop-off selection change versus when dropping off in daylight (often, the answer is yes). Is it raining or snowing, and if so, does that impact the drop-off choice (usually, yes)? Is there any road repair taking place near to the destination and does that impact the options for doing the drop-off (yes)?
If you are saying to yourself that the passenger ought to take fate into their own hands and tell the AI system where to drop them off, yes, some AI developers are incorporating Natural Language Processing (NLP) that can interact with the passengers for such situations, though this does not entirely solve this drop-off problem.
Why?
Because the passenger might not know what is a good place to drop-off.
I’ve had situations whereby I argued with a ridesharing driver or cabbie about where I thought I should be dropped-off, yet it turned out their local knowledge was more attuned to what was a prudent and safer place to do so.
Plus, in the case of autonomous cars, keep in mind that the passengers in the driverless car might be all children and no adults. This means that you are potentially going to have a child trying to decide what is the right place to be dropped off.
I shudder to think if we are really going to have an AI system that lacks any semblance of common-sense be taking strict orders from a young child, whereas an adult human driver would be able to counteract any naïve and dangerous choice of drop-offs (presumably, hopefully).
For the use of Natural Language Processing in socio-conversations, see my discussion here: https://aitrends.com/features/socio-behavioral-computing-for-ai-self-driving-cars/
For my explanation about why it is that AI self-driving cars will need to drive illegally, see this link: https://aitrends.com/selfdrivingcars/illegal-driving-self-driving-cars/
For the role of children as riders in AI autonomous cars, see my indication here: https://www.aitrends.com/ai-insider/children-communicating-with-an-ai-autonomous-car/
For my insights about how nighttime use of AI self-driving cars can be difficult, see this link: https://www.aitrends.com/ai-insider/nighttime-driving-and-ai-autonomous-cars/
For the role of ODD’s in autonomous cars, here’s my discussion: https://www.aitrends.com/ai-insider/amalgamating-of-operational-design-domains-odds-for-ai-self-driving-cars/
More On The Drop-off Conundrum
The drop-off topic will especially come to play for self-driving cars at a Level 4, which is the level at which an autonomous car will seek to pullover or find a “minimal risk condition” setting when the AI has reached a point that it has exhausted its allowed Operational Design Domain (ODD). We are going to have passengers inside Level 4 self-driving cars that might get stranded in places that are not prudent for them, including say young children or perhaps someone elderly and having difficulty caring for their own well-being.
It has been reported that some of the initial tryouts of self-driving cars revealed that the autonomous cars got flummoxed somewhat when approaching a drop-off at a busy schoolground, which makes sense in that even as a human driver the chaotic situation of young kids running in and around cars at a school can be unnerving.
I remember when my children were youngsters how challenging it was to wade into the morass of cars coming and going at the start of school day and at the end of the school day.
One solution apparently for the reported case of the self-driving cars involved re-programming the drop- off of its elementary school aged passengers at a corner down the street from the school, thus apparently staying out of the traffic foray.
In the case of my own children, I had considered doing something similar, but subsequently realized that it meant they had a longer distance to walk to school, providing other potential untoward aspects and that it made more sense to dig into the traffic and drop them as closely to the school entrance as I could get.
Some hope that Machine Learning and Deep Learning will gradually improve the AI driving systems as to where to drop off people, potentially learning over time where to do so, though I caution that this is not a slam-dunk notion (partially due to the lack of common-sense reasoning for AI today).
Others say that we’ll just all have to adjust to the primitive AI systems and have all restaurants, stores, and other locales all stipulate a designated drop-off zone.
This seems like an arduous logistics aspect that would be unlikely for all possible drop-off situations. Another akin approach involves using V2V (vehicle-to-vehicle) electronic communications, allowing a car that has found a drop-off spot to inform other nearing cars as to where the drop-off is. Once again, this has various trade-offs and is not a cure-all.
Conclusion
It might seem like a ridiculous topic to some, the idea of worrying about dropping off people from autonomous cars just smacks of being an overkill kind of matter.
Just get to the desired destination via whatever coordinates are available, and make sure the autonomous car doesn’t hit anything or anyone while getting there.
The thing is, the last step, getting out of an autonomous car, might ruin your day, or worse lose a life, and we need to consider holistically the entire passenger journey from start to finish, including where to drop-off the humans riding in self-driving driverless cars.
It will be one small step for mankind, and one giant leap for AI autonomous cars.
Copyright 2020 Dr. Lance Eliot
This content is originally posted on AI Trends.
[Ed. Note: For reader’s interested in Dr. Eliot’s ongoing business analyses about the advent of self-driving cars, see his online Forbes column: https://forbes.com/sites/lanceeliot/]

AI Careers: Kesha Williams, Software Engineer, Continues Her Exploration

By John P. Desmond, AI Trends Editor
We recently had a chance to catch up on the career of Kesha Williams, software engineer, author, speaker and instructor. AI Trends published an Executive Interview with Kesha in June 2018. At the time she was in the Information Technology department at Chick-fil-A, the restaurant chain, with responsibility to lead and mentor junior software engineers, and deliver on innovative technology.
She decided to move on from Chick-fil-A after 15 years in June 2019. Now she works at A Cloud Guru, an online education platform for people interested in cloud computing. Most of the courses prepare students for certification exams. The company was established in Melbourne, Australia in 2015.
“I wanted a role that allowed me to be more hands on with the latest, greatest technology,” she said in a recent interview. “And I wanted to be able to help people on a broader scale, on a more global level. I always felt my part of being here on the planet is to help others, and more specifically to help those in tech.”

A Cloud Guru offers certifications for Amazon Web Services (AWS), Microsoft Azure and Google Cloud. It also has what Williams calls “cloud adjacent” courses including on Python programming and machine learning. “These courses will help you ‘skill up’ in the cloud and prepare for certification exams,” she said.
Kesha’s role is as a training architect, focusing on online content around AWS, specifically in the AI space. “Many people have taken this time being at home, to work on skills or learn something new. It’s a great way to spend time during the lockdown,” she advised. A true techie.
AWS DeepComposer Helps Teach About Generative AI and GANs
Most recently, she has been using AWS DeepComposer, an educational training service through AWS that allows the user to compose music using generative AI and GANs (generative adversarial networks, a class of machine learning frameworks). “I have been learning about that, so I can teach others about machine learning and music composition,” she said.
Using music samples, the user trains a music genre model. That model learns how to create new music, based on studying the music files you upload to it. The user plays a melody on a keyboard, gives it to the model, the model composes a new song by adding instruments. She is working on a web series to teach students about that process.
“It’s a fun way to teach some of the more complex topics of GANs and machine learning,” she said. Fortunately she can fall back on youth choir days playing the piano. “I’m remembering things,” she said.
Amazon makes it easy to start out, not charging anything for up to 500 songs. A student can buy the keyboard for $99, or use a virtual keyboard available on the site. Behind the scenes, Amazon SageMaker is working. That will cost some money if the student continues. (SageMaker is a cloud machine-learning platform, launched in November 2017. It enables developers to create, train and deploy machine-learning models in the cloud, or on edge devices.)
So far, Williams has done about 30 songs. “I have used my machine learning skills to train my own genre model. I trained a reggae model; I love reggae.”
Kesha’s Korner is a blog on A Cloud Guru where Williams introduces people to machine learning, offering four to six-minute videos on specific topics. The videos are free to watch; pricing for the A Cloud Guru courses come with membership priced from $32/mo to $49/mo depending, “It’s been a fun series to demystify machine learning,” she said. “It generates a lot of conversations. I often receive feedback from students on which topics to talk about.”
Woman Who Code Planning Virtual Conference
Women Who Code is another interest. The organization works to help women be represented as technical leaders, executives, founders, venture capitalists, board members and software engineers.
The Connect Digital 2020 is the organization’s first entirely virtual conference, to be held on three successive Fridays in June, with Williams scheduled for Friday, June 19. At that meeting, she will deliver a talk about using machine learning for social good, then kick off a “hackathon” to start the following week. The hackathon will start with three technical workshops, the first an introduction to machine learning tools, the second about preparing data, the third about building models. “Their challenge is to take everything they have learned and use machine learning to build a model to help battle the spread of the Covid-19 virus,” she said. “They will have a month to go off and build it, then present it to a panel of judges.” The winner receives a year of free access to the A Cloud Guru platform.
“There are a lot of software engineers that want to make a transition to data science and machine learning,” she said.
Asked what advice she would have for young people or early-career people interested in exploiting AI, Williams said, “Whenever I try to demystify machine learning for people, I tell them it’s complex, but not as complex as most people make it out to be. I thought at first you needed a PhD and to work in a research lab to grasp it. But there are many tools and services out there, especially from AWS, that make these complex technologies approachable and affordable to play around with.
“When you are first learning, you will make a lot of mistakes,” she said. “Don’t beat yourself up. Just stay at it.”
Williams has concerns about AI going forward. “I have always been concerned about the lack of diversity in AI, about the bias issues and the horror stories we have seen when it comes to certain bad-performing models that are used to make decisions about people. It’s still an issue; we need to continue to talk about it and solve it.”
Being in information technology for 25 years has been and continues to be a good career. “It’s still exciting for me. Every day there is something new to learn.”
Learn more at Kesha’s Korner and Women Who Code.
Federal Government Inching Toward Enterprise Cloud Foundation

By AI Trends Staff
The federal government continues its halting effort to field an enterprise cloud strategy, with Lt. Gen. Jack Shanahan, who leads the Defense Department’s Joint AI Center (JAIC), commenting recently that not having an enterprise cloud platform has made the government’s efforts to pursue AI more challenging.
“The lack of an enterprise solution has slowed us down,” stated Shanahan during an AFCEA DC virtual event held on May 21, according to an account in FCW. However, “the gears are in motion” with the JAIC using an “alternate platform” for example to host a newer anti-COVID effort.

This platform is called Project Salus, and is a data aggregation that is able to employ predictive modeling to help supply equipment needed by front-line workers. The Salus platform was used for the ill-fated Project Maven, a DOD effort that was to employ AI image recognition to improve drone strike accuracy. Several thousand Google employees signed a petition to protest the company’s pursuit of the contract, and Google subsequently dropped out.
Shanahan recommends the enterprise cloud project follow guidance of the Joint Common Foundation, an enterprise-wide, multi-cloud environment set up as a transition to the Joint Enterprise Defense Infrastructure program (JEDI). The JEDI $10 billion DOD-wide cloud acquisition was won by Microsoft in October, was challenged by Amazon and has been stuck in legal battles since.
“It’s set us back, there’s no question about it, but we now have a good plan to account for the fact that it will be delayed potentially many more months,” Shanahan stated.
That plan involves a hybrid approach of using more than one cloud platform. At Hanscom Air Force Base in Bedford, Mass., for instance, the Air Force’s Cloud One environment is using both Microsoft Azure and Amazon Web Services.
“I will never get into a company discussion, I’m agnostic. I just need an enterprise cloud solution,” Shanahan stated. “If we want to make worldwide updates to all these algorithms in the space of minutes not in the space of months running around gold discs, we’ve got to have an enterprise cloud solution.”
Joint Common Foundation Aims to Set Up Migration to JEDI
The Joint Common Foundation, announced in March, is an enterprise cloud-based foundation intended to provide the development, test and runtime environment—and the collaboration, tools, reusable assets and data—that the military needs to build, refine, test and field AI applications, according to a JAIC AI Blog post.
“The Infrastructure and Platform division is building an enterprise cloud-enabled platform across multiple govCloud environments in preparation for the JEDI migration,” stated Denise Hodge, Information Systems Security Manager, who is leading the effort to develop the Joint Common Foundation.

The JCF has the following design goals:
- Reduce technical barriers to DoD-wide AI adoption.
- Accelerate security assessments of AI products to support rapid authorization decisions and AI capability deployment.
- Create standardized development, security, testing tools, and practices to support secure, scalable AI development.
- Facilitate the concept of secure re-use of AI resources, software, tools, data, and lessons learned that capitalize on the progress made by each JCF AI project.
- Encourage efficiencies by finding patterns in JCF customer needs and creating solutions that are repeatable to build core products that advance AI development
- Mitigate risk by providing a common, standardized, and cyber-hardened infrastructure and platform for AI development, assessments, and rapid deployment promotion.
Hodge has spent much of her career supporting Chief Information Officers and Authoring Officials in various IT ecosystems in the Department of Defense, concentrating especially on cybersecurity. “Cybersecurity is the thread that binds the enterprise cloud together,” she stated.
She described four pillars of security to promote cyber engagement and governance: infrastructure security; secure ingest, ongoing authorization and continuous monitoring.
“This initiative is to provide a common, standardized, and hardened development platform that promotes a secure AI development ecosystem,” Hodges stated.
JEDI Project Tied Up in Court
In court documents released in March, Amazon argued that the Pentagon’s proposed corrective action approach over the disputed $10 billion cloud contract, is not a fair re-evaluation, according to an account from CNBC.
Amazon was seen as the favorite to win the JEDI contract, until President Donald Trump got involved. Amazon alleges that the President launched “behind the scenes attacks” against Amazon. Some of them were detailed in the memoir of James Mattis, the retired Marine Corps general who served as US Secretary of Defense from January 2017 through January 2019. In the memoir, Mattis stated that President Trump told him to “screw Amazon” out of the contract.
Amazon is seeking to depose a number of people involved in the JEDI recommendation. The dispute is ongoing.
Read the source articles at FCW, JAIC AI Blog post and CNBC.
Determining the ROI of AI Projects A Key to Success

By John P. Desmond, Editor, AI Trends
The best practices around determining whether your AI project will achieve a return for the business center around determining at the outset how the return on investment will be measured.
The evidence shows it will be time well spent. An estimated 87% of data science projects never make it to the production stage, and 56% of global CEOs expect it to take three to five years to see any real ROI on AI investments, according to a recent account in Forbes.
Like any other technology investment, business leaders need to define the specific goals of the AI projects, and commit to tracking it with benchmarks and key performance indicators, suggested author Mark Minevich, Advisor to Boston Consulting Group, venture capitalist and cognitive strategist. The company needs to think about the types of business problems that can be addressed with AI, so as not to set unrealistic expectations and not set the AI off in search of a business problem to solve.

Figuring out how to assign the people needed to help with the project is crucial. Some companies are using virtual teams where data scientists might work with an operations team two days a week. To break down the organization silos and allow various stakeholders to interact and collaborate, is a critical enabler of an AI project.
Employees need to be prepared. Investments in reskilling employees in AI need to be made, including for management in how to work in cross-functional teams across operations.
Every company engaged in AI projects is challenged to measure ROI. Author Minevich suggests focusing on what the project will save instead of potential revenue growth. “How much you invest in AI should be based on these saving forecasts and not revenue uplift,” he stated. That way, “If the deployment is not successful, the organization will have risked only what it expected to save, rather than risking what it expected to add in revenue.”
He also suggested knowing where the break-even point will be, when the cost savings of the project equals the investment. Many organizations struggle with predicting the break-even point, but using cost savings can allow a reasonable prediction to be made at the outset.
Some Dramatic Returns are Being Seen
While some 40% of organizations making significant investments in AI projects are not reporting business gains, others are seeing dramatic returns, according to a recent account in KungFuAI.
The top reasons AI projects fail were found to be: lack of vision, meaning the projects lacked a clear business purpose or was not rooted in a problem with a known business case worth solving; bad data, with no way to collect, store and make relevant data accessible; the company culture is not embracing emerging technologies in operations and do not have strong data literacy; and not enough patience, expecting results too soon.
Suggestions: pick business problems or challenges that are easy to measure; deploy for targeted use cases; include many stakeholders; track small milestones. A narrow solution can contribute to the business case, if it does not solve the whole problem.
Customer Experience Experts Face Challenge of AI ROI
The biggest barrier to implementation of AI for experts in customer experience, is determining ROI, according to a recent account from CX Network. The organization surveyed 102 experts in customer experience; 36% cited this challenge, followed by 35% saying company culture was the major impediment, followed by competing priorities, cited by 31%.

“Innovation of any kind cannot be expected to generate returns right away, so if you are embarking on something brand new ensure you have the buy-in from leadership. This includes the flexibility to fail a little along the way,” stated Jon Stanesby, director of product strategy for AI Application at Oracle, on linking initiatives to ROI. He also suggested factoring in the impact of reduced effort required by human workers on the AI is deployed.
McKinsey has estimated that AI can deliver additional global economic activity of about $13 trillion by 2030, amounting to an additional 1.2% of GDP growth each year, a rate comparable to the effect of other revolutionary innovations. The returns are out there for those that set up AI projects to be successful.
Read the source articles in Forbes, at KungFuAI and in CX Network.
Intel, Penn Medicine Launch Federated Learning Model For Brain Tumors
By Allison Proffitt, Editorial Director, AI Trends
The University of Pennsylvania and Intel have built a federation of 30 institutions to use federated learning to train artificial intelligence (AI) models to identify boundaries of brain tumors.
Led by Spyridon Bakas at the Center for Biomedical Image Computing and Analytics (CBICA) at the Perelman School of Medicine at the University of Pennsylvania, the federation is the next step forward in a years-long effort to gather data that would empower AI in brain image analysis.
“During my last few years of research, I’ve been focusing on learning predictive models of brain tumor segmentation, predicting genomics, predicting overall survival of patients from baseline scans…, evaluating the propensity of the tumor to be more aggressive by various means, toward improving the clinical outcome of patients,” Bakas told Bio-IT World.
Brain tumors have multiple, sensitive sub-compartments that show up in different scans in different ways: active parts of the tumor that are really vascularized, necrotic parts of the tumor where tissue has died, and parts of tumors that are infiltrating healthy tissue.
“An abnormality in the brain is fairly easy for someone to spot,” Bakas said. Applying AI to the problem, “is not to detect whether there is a tumor or not; it’s to detect the boundaries of the tumor.”

Bakas has been leading the International Brain Tumor Segmentation Challenge (BraTS) since 2017. The annual challenges, which began in 2012, evaluates state-of-the-art methods for the segmentation of brain tumors in multimodal magnetic resonance imaging (MRI) scans. Along the way, Bakas explained, he became very familiar with the hurdles of putting together a centralized dataset to serve as the community benchmark dataset for BraTS. Participants were concerned about privacy both from institutional and cultural perspectives. Organizations were only willing to share MRI images on a few dozen patients.
After nearly ten years of the BraTS challenge, the group has assembled a cumulative dataset from 650 adult patients consisting of four images from each patient.
But each member institution has at least this much data, Bakas explained. “If there were no privacy or data ownership concerns, we should have instead 650 x 21 [patients]—a full dataset from each of the institutions involved in BraTS.”
Surely there was a solution.
Bakas, a computational scientist by training, began thinking of machine learning approaches. At a conference in early 2018 he met researchers from Intel AI and Intel Labs. “We came up with this idea: utilizing federated machine learning in medicine for medical images.”
Enter Intel
Federated learning was first introduced by Google in 2017 and used to train autocorrect models for texting. Data owners train a model architecture locally using only their own data. Each model is then shared with an aggregation server, which creates a consensus model of all the accumulated knowledge from the data owners, even though the raw data never leave their institutions.
Jason Martin, principal engineer at Intel Labs and a privacy researcher, had been exploring ways to apply federated learning, particularly in privacy-sensitive domains.

“As we looked at [federated learning], we realized we could contribute some security and privacy technology and domain knowledge to it,” Martin said. “We began looking at what important use cases would benefit from this sort of privacy-preserving federated learning.”
Medical images made sense, so Bakas, Martin, and their colleagues started with a feasibility study: creating a faux federated learning system using the BraTS data already in hand. Could a federated learning model train an algorithm to the same accuracy as pooled data?
The team split the donated BraTS data roughly in half. Data from nine institutions was used for validation and training of the pooled model; data from 10 institutions was split by home institution and trained in a federated way—as if it had never been shared at all.
“We trained an AI model on the centralized data that was all shared. Then we obtained performance X,” Bakas explained. “Then we took the data, distributed it as if it was not shared, and applied the federated approach. We trained the model on each institution’s data and we aggregated it in a way to create a consensus model.”
The team found that the two groups performed nearly identically. The performance of the federated semantic segmentation models on multimodal brain scans had a Dice Coefficient of 0.852 while the models trained by sharing data had a Dice Coefficient of 0.862. (A Dice Coefficient of 1 would be perfect alignment between the model and reality.)
“The federated model was performing 99% to the performance of the model trained on centralized data,” Bakas said.
This feasibility study was delivered in 2018 at the International MICCAI Brainlesion Workshop (DOI: 10.1007/978-3-030-11723-8_9). Bakas and Martin are both authors.
“We were the first to demonstrate that if you split that data back up to the original 10 medical institutions that donated it, and treated them as a federation instead of a central donation, that you could get almost the same segmentation performance out of the machine learning model,” Martin said. “That was very exciting!”
And it’s on that foundation that the new federation will be built.
Bakas was awarded a grant by the Informatics Technology for Cancer Research (ITCR) program of the National Cancer Institute (NCI) of the National Institutes of Health (NIH) to explore the idea further. The three-year, $1.2 million grant funds Penn Medicine’s work developing the Federated Tumor Segmentation (FeTS) platform, open-source toolkit, and user-friendly GUI. Penn Medicine brings the medical imaging and machine learning competence, Bakas explained. Intel Labs is the technology provider and brings all the security and privacy expertise.
“We’ve been working with Spyros to create a real federated learning platform—the actual software and infrastructure components that are necessary for multiple institutions to collaborate across the public internet,” Martin said.
New Federation, New Questions
Although the feasibility study was very promising for the accuracy of federated learning, there are still questions to be answered. How would such a federation behave in the real world? What are the privacy risks? How much work will federated learning be for the data-hosting institutions?
“We know some of the answers to those questions, and frankly some of them I expect we’re going to learn as we go,” Martin said.
The original BraTS group included 19 institutions; the current federation numbers 30 groups. All of the federation members are research institutions and have committed research effort, not just data, to the project.
There will be significant work for data host institutions, at least at first. The federated learning model is a supervised learning model. The data must be annotated by hand. In this case, a radiologist at each member organization will label tumors in the MRI images according to a protocol established through BraTS. That is a costly step. In the future—at a much larger scale—a federated learning model could shift to unsupervised learning, lessening some of the load for participating institutions.
Other big questions for data hosts will focus on privacy and bandwidth. Martin expects the earliest federation members will likely move the data they have committed to use for model training to a separate server for greater privacy. In theory, of course, those data won’t leave the institution, but the model architecture will come and go via the internet. “It will take some time, I think, to gain comfort with something that has internet connectivity being connected to, say, the healthcare systems themselves,” he said.
Some of the challenges in a federated learning model are simply social and relational: building trust within the group. It’s very important, Martin argues, that all of the participants trust that others are playing by the same rules. Hardware can help.
“A lot of our focus here at Intel has been on ensuring that, when [the federation is] deployed, the parties participating can trust each other to contribute fairly, and that the rules of engagement—if you will—are enforced by the hardware platforms and the software that we’re developing,” Martin explained.
But the whole model still requires interpersonal trust.
“The platform we’re creating still requires that you come to the table—or virtual table—and you decide on your experiments or your goals,” Martin said. “Once you agree on them, then those are the rules that we want to enforce through the mechanisms in the system architecture. What you agree to at the table can’t be compromised either intentionally or unintentionally by malware or bad actors that come into the system.”
Open Model
The Federation itself is just launching. Martin’s team is tackling, “what you might consider some of the boring parts of the federation,” he explained: “getting the number of connections working and such. We’re hardening that software to the point where it can be deployed to the remainder of the federation.”
Bakas and his lab are, “in the process of actually serving the algorithm for phase two to the outside institutions.” The software will be made available open source, he said. “We want this framework to be publicly available. We don’t want to create a proprietary software that someone needs to pay a license or use to build upon.” Bakas believes the framework could be easily applied to other disease areas or even data types.
Once the software is in place, each “federated round”—one cycle of training the model architecture at the data hosts and then sending it back to the aggregator—will take “on the scale of days to weeks,” Martin predicts.
This won’t be a one-and-done circuit. Returning the consensus model back to the member institutions will deliver clinical impact, Bakas says, and it will only improve as more diverse data are included. The model will improve as well. Federated learning enables researchers to explore new model architectures—hyperparameters—and tune the model. Bakas and his team at Penn Medicine will be able to refine the machine learning models with the additional data federated learning makes available.
Thursday, 28 May 2020
Announcing a New Redash Connector for Databricks
We’re happy to introduce a new, open source connector with Redash, a cloud-based SQL analytics service, to make it easy to query data lakes with Databricks. Traditionally, data analyst teams face issues with stale and partial data compromising the quality of their work, and want to be able to connect to the most complete and recent data available in data lakes, but their tools are often not optimized for querying data lakes. We’ve been working with the Redash team to improve a new Databricks connector that makes it easy for analysts to perform SQL queries and build dashboards directly against data lakes, including open source Delta Lake architectures, to deliver better decision making and insights.
Redash and Databricks Overview
Redash is an open source SQL-based service for analytics and dashboard visualizations. It offers a familiar SQL editor interface to browse the data schema, build queries, and view results that should be familiar to anyone who’s worked with a relational database. Queries can be easily converted into visualizations for quick insights, connected to alerts to notify on specific data events, or managed by API for automated workflows. Live web-based reports can be shared, refreshed, and modified by other teams for easy collaboration. These capabilities are driven by the Redash open source community, with over 300 contributors and more than 7,000 open source deployments of Redash globally.
With the new, performance-optimized and open source connector, Redash offers fast and easy data connectivity to Databricks for querying your data lake, including Delta Lake architectures. Delta Lake adds an open source storage layer to data lakes to improve reliability and performance, with data quality guarantees like ACID transactions, schema enforcement, and time travel, for both streaming and batch data in cloud blob storage. An optimized Spark SQL runtime running on scalable cloud infrastructure provides a powerful, distributed query engine for these large volumes of data. Together, these storage and compute layers on Databricks ensure data teams get reliable SQL queries and fast visualizations with Redash.
How to get started with the Redash Connector
You can connect Redash to Databricks in minutes. After creating a free Redash account, you’re prompted to connect to a “New Data Source”. Select “Databricks” as the data source from the menu of available options.

The next screen prompts you for the necessary configuration details to securely connect to Databricks. You can check out the documentation for more details.

With the Databricks data source connected, you can now run SQL queries on Delta Lake tables as if it were any other relational data source, and quickly visualize the query results.

Recap
Combining Redash’s open source SQL analytics capabilities with Databricks’s open data lakes gives SQL analysts an easy and powerful way to edit queries and create visualizations and dashboards directly on the organization’s most recent and complete data. Learn more from the Redash documentation.
--
Try Databricks for free. Get started today.
The post Announcing a New Redash Connector for Databricks appeared first on Databricks.
Automating away engineering on-call workflows at Databricks
A Summer of Self-healing
This summer I interned with the Cloud Infrastructure team. The team is responsible for building scalable infrastructure to support Databricks’s multi-cloud product, while using cloud-agnostic technologies like Terraform and Kubernetes. My main focus was developing a new auto-remediation service, Healer, which automatically repairs our Kubernetes infrastructure to improve our service availability and reduce on-call burden.
Automatically Reducing Outages and Downtime
The Cloud Infra team at Databricks is responsible for underlying compute infrastructure for all of Databricks, managing thousands of VMs and database instances across clouds and regions. As components in a distributed system, these cloud-managed resources are expected to fail from time to time. On-call engineers sometimes perform repetitive tasks to fix these expected incidents. When a PagerDuty alert fires, the on-call engineer manually addresses the problem by following a documented playbook.
Though ideally we’d like to track down and fix the root cause of every issue, to do so would be prohibitively expensive. For this long tail of issues, we instead rely on playbooks that address the symptoms and keep them in check. And in some cases, the root cause is a known issue with one of the many open-source projects we work with (like Kubernetes, Prometheus, Envoy, Consul, Hashicorp Vault), so a workaround is the only feasible option.
On-call pages require careful attention from our engineers. Databricks engineering categorizes issues based on priority. Lower-priority issues will only page during business hours (i.e. engineers won’t be woken up at night!). For example, if a Kubernetes node is corrupt in our dev environment, the on-call engineer will only be alerted the following morning to triage the issue. Since Databricks engineering is distributed worldwide (with offices in San Francisco, Toronto, and Amsterdam) and most teams are based out of a single office, an issue with the dev environment can impede certain engineers for hours, decreasing developer productivity.
We are always looking for ways to reduce our keeping-the-lights-on (KTLO) burden, so designing a system that responds to alerts without human intervention by executing engineer-defined playbooks makes a lot of sense to manage resources at our scale. We set out to design a system that would help us address these systemic concerns.
Self-healing Architecture

The Healer architecture is composed of input events (Prometheus/Alertmanager), execution (Healer endpoint, worker queue/threads), and actions (Jenkins, Kubernetes, Spinnaker jobs).
Healer is designed using an event-driven architecture that autonomously repairs the Kubernetes infrastructure. Our alerting system (Prometheus, Alertmanager) monitors our production infrastructure and fires alerts based on defined expressions. Healer runs as a backend service listening to HTTP requests from Alertmanager with alert payloads.
Using the alert metadata, Healer constructs the appropriate remediation based on the alert type and the alert labels. A remediation dictates what the remediation action will be as well as any parameters needed.
Each remediation is scheduled onto a worker execution thread pool. The worker thread will run the respective remediation by making calls to the appropriate service and then monitor the remediation for completion. In practice, this could be kicking off a Jenkins, Kubernetes, or Spinnaker job that automates the manual script workflow. We choose to support these frameworks, because they provide Databricks engineers with a wide ability to customize actions in reaction to the alerts.
Once the remediation completes, JIRA and Slack notifications are sent to the corresponding team confirming remediation task completion.
Healer can be easily extended with new kinds of remediations. Engineering teams outside of Cloud Infra can onboard remediations jobs that integrate with their service alerts, taking needed actions to recover from incidents, reducing on-call load generally across engineering.
Example Use Case
One use case for Healer is for remediating low disk space on our Kubernetes nodes. The on-call engineer is notified of this problem by an alert called “NodeDiskPressure”. To remedy NodeDiskPressure, an on-call engineer would connect to the appropriate node and execute a docker image prune command.
To automate this, we first develop an action to be triggered by Healer; we define a Jenkins job called DockerPruneNode, which automates the manual steps equivalent to connecting to a node and executing docker image prune. We then configure a Healer remediation to resolve NodeDiskPressure alerts automatically by defining a Healer rule that binds an exact remedy (DockerPruneNode) given an alert and its parameters.
Below is an example of how a NodeDiskPressure alert gets translated into a specific remediation including the job to be run and all the needed parameters. The final remediation object has three “translated” params taken from the alert as well as one “static” hard-coded param.

Example repair initiated by the Databricks auto-remediation service Healer for a NodeDiskPressure alert.
The configuration also has a few other parameters which engineers can configure to tune the exact behavior of the remediation. They are omitted here for brevity.
After defining this rule, the underlying issue is fully automated away, allowing on-call engineers can focus on other more important matters!
Future Steps
Currently Healer is up, running, and improving availability of our development infrastructure. What do next steps for the service look like?
Initially, we plan to onboard more of the Cloud Infra team’s use cases. Specifically, we are looking at the following use cases:
- Support fine-grained auto-scaling to our clusters by leveraging existing system usage alerts (CPU, memory) to trigger a remediation that will increase cluster capacity.
- Terminate and reprovision Kubernetes nodes that are identified as unhealthy.
- Rotate service TLS certifications when they are close to expiring.
Furthermore, we want to continue to push adoption of this tool within the engineering organization and help other teams to onboard their use cases. This general framework can be extended to other teams to reduce their on-call load as well.
I am looking forward to seeing what other incidents Healer can help remediate for Databricks in the future!
Special thanks for a great internship experience to my mentor Ziheng Liao, managers Nanxi Kang and Eric Wang, as well as the rest of the cloud team here at Databricks!
I really enjoyed my summer at Databricks and encourage anyone looking for a challenging and rewarding career in platform engineering to join the team. If you are interested in contributing to our self-healing architecture, check out our open job opportunities!
--
Try Databricks for free. Get started today.
The post Automating away engineering on-call workflows at Databricks appeared first on Databricks.
How to Implement Manufacturing Process Data Automation in Your Business?
Data Automation has now become one of the latest trends in most of the industries, including manufacturing. With the highly competitive atmosphere in the industry, manufacturers have turned to automation to save time and effort in labor-intensive processes. You can automate the way of capturing data, sharing it, and storing it with advanced mobile-based and cloud technologies. Let’s see how you can implement automation in your manufacturing business.Using Industrial Internet of Things to automate manufacturing businesses–Internet of Things (IoT)-based applications are the most profitable options in a business where faster development and product quality are the major factors to gain a higher Return on Investment (ROI). We have found a myriad of ways how IoT is benefiting the manufacturing sector.Manage supply chainIoT-enabled platforms enable you to track the global and local inventory systems. Manufacturing companies can inspect their supply chains regularly. They will get real-time information on the work status, delivery dates, and equipment collection. Thus, there is no need to create a manual documentation related to everyday operations.Workshop mirroring-Industrial Internet of Things can help in connecting the information management system and market-ready solutions. You can automate the process of controlling IoT-enabled manufacturing processes in workshops.Ensure safetyDue to equipment defects, ...
Read More on Datafloq
Read More on Datafloq
How AI is Changing the Marketing Landscape
AI—artificial intelligence—is set to become the core of marketing strategies from 2020 onwards.The current global situation has impacted how businesses work—and the changes are likely to continue into the future.With digital marketing strategies being strongly affected, the focus for businesses has had to adapt. While social media and SEO content has its place, AI is where the future lies.Over the years, AI has seen a few ups and downs—some of the AI errors in live chats have been meme-d relentlessly.But the AI of old has seen massive improvements—and it’s fast becoming the future tech all companies want to adopt.We look at how AI is changing the marketing landscape in 2020.1. Customer AcquisitionThe digital world is powered by data—now more so than before because of the number of people who are online. The data generated from social media and website visits give marketers information about their target market.Details such as demographics, interests, and pain points can be generated, giving marketers insights into their potential customers.But while data is handy, it doesn’t complete the profile of the customer. For a thorough understanding of the audience, one needs to analyze the data and make inferences.And the reason why data analysis is becoming so ...
Read More on Datafloq
Read More on Datafloq
The space business is about to get really serious
For years, the U.S. has been buying rides to space from Russia, spending $3.5 billion for 52 rides since 2011. Instead of turning to Russia, NASA will now rely on private-sector spacecraft.
Wednesday, 27 May 2020
Modernizing Risk Management Part 1: Streaming data-ingestion, rapid model development and Monte-Carlo Simulations at Scale
Managing risk within the financial services, especially within the banking sector, has increased in complexity over the past several years. First, new frameworks (such as FRTB) are being introduced that potentially require tremendous computing power and an ability to analyze years of historical data. At the same, regulators are demanding more transparency and explainability from the banks they oversee. Finally, the introduction of new technologies and business models means the need for sound risk governance is at an all time high. However, the ability for the banking industry to effectively meet these demands has not been an easy undertaking. Traditional banks relying on on-premises infrastructure can no longer effectively manage risk. Banks must abandon the computational inefficiencies of legacy technologies and build an agile Modern Risk Management practice capable of rapidly responding to market and economic volatility through the use of data and advanced analytics. Recent experience shows that as new threats emerge, historical data and aggregated risk models lose their predictive values quickly. Risk analysts must augment traditional data with alternative datasets in order to explore new ways of identifying and quantifying the risks facing their business, both at scale and in real-time.
In this blog, we will demonstrate how to modernize traditional value-at-risk (VaR) calculation through the use of various components of the Databricks Unified Data Analytics Platform — Delta Lake, Apache SparkTM and MLflow — in order to enable a more agile and forward looking approach to risk management.

This first series of notebooks will cover the multiple data engineering and data science challenges that must be addressed to effectively modernize risk management practices:
- Using Delta Lake to have a unified view of your market data
- Leveraging MLflow as a delivery vehicle for model development and deployment
- Using Apache Spark for distributing Monte Carlo simulations at scale
The ability to efficiently slice and dice your Monte Carlo simulations in order to have a more agile and forward-looking approach to risk management will be covered in a second blog post, focused more on a risk analyst persona.
Modernizing data management with Delta Lake
With the rise of big data and cloud based-technologies, the IT landscape has drastically changed in the last decade. Yet, most FSIs still rely on mainframes and non-distributed databases for core risk operations such as VaR calculations and move only some of their downstream processes to modern data lakes and cloud infrastructure. As a result, banks are falling behind the technology curve and their current risk management practices are no longer sufficient for the modern economy. Modernizing risk management starts with the data. Specifically, by shifting the lense in which data is viewed: not as a cost, but as an asset.
Old Approach: When data is considered as a cost, FSIs limit the capacity of risk analysts to explore “what if“ scenarios and restrict their aggregated data silos to only satisfy predefined risk strategies. Over time, the rigidity of maintaining silos has led engineers to branch new processes and create new aggregated views on the basis of already fragile workflows in order to adapt to evolving requirements. Paradoxically, the constant struggle to keep data as a low cost commodity on-premises has led to a more fragile and therefore more expensive ecosystem to maintain overall. Failed processes (annotated as X symbol below) have far too many downstream impacts in order to guarantee both timeliness and reliability of your data. Consequently, having an intra-day (and reliable) view of market risk has become increasingly complex and cost prohibitive to achieve given all the moving components and inter-dependencies as schematised in below diagram.
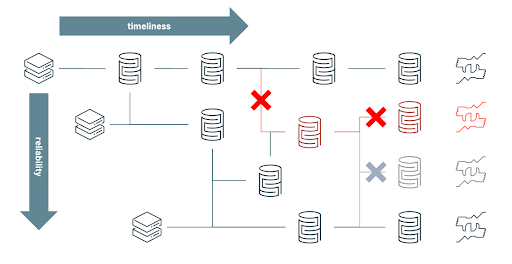
Modern Approach: When data is considered as an asset, organizations embrace the versatile nature of the data, serving multiple use cases (such as value-at-risk and expected shortfall) and enabling a variety of ad-hoc analysis (such as understanding risk exposure to a specific country). Risk analysts are no longer restricted to a narrow view of the risk and can adopt a more agile approach to risk management. By unifying streaming and batch ETL, ensuring ACID compliance and schema enforcement, Delta Lake brings performance and reliability to your data lake, gradually increasing the quality and relevance of your data through its bronze, silver and gold layers and bridging the gap between operation processes and analytics data.

In this demo, we evaluate the level of risk of various investments in a Latin America equity portfolio composed of 40 instruments across multiple industries, storing all returns in a centralized Delta Lake table that will drive all our value-at-risk calculations (covered in our part 2 demo).

For the purpose of this demo, we access daily close prices from Yahoo finance using python yfinance library. In real life, one may acquire market data from source systems directly (such as change data capture from mainframes) to a Delta Lake table, storing raw information on Bronze and curated / validated data on a Silver table, in real-time.
With our core data available on Delta Lake, we apply a simple window function to compute daily log returns and output results back to a gold table ready for risk modelling and analysis.
@udf("double")
def compute_return(first, close):
return float(np.log(close / first))
window = Window.partitionBy('ticker').orderBy('date').rowsBetween(-1, 0)
spark \
.read \
.table(stock_data_silver) \
.withColumn("first", F.first('close').over(window)) \
.withColumn("return", compute_return('first', 'close')) \
.select('date', 'ticker', 'return')
.write \
.format("delta") \
.mode("overwrite") \
.saveAsTable(stock_data_gold)
In the example below, we show a specific slice of our investment data for AVAL (Grupo Aval Acciones y Valores S.A), a financial services company operating in Columbia. Given the expected drop in its stock price post march 2020, we can evaluate its impact on our overall risk portfolio.

Streamlining model development with MLFlow
Although quantitative analysis is not a new concept, the recent rise of data science and the explosion of data volumes has uncovered major inefficiencies in the way banks operate models. Without any industry standard, data scientists often operate on a best effort basis. This often means training models against data samples on single nodes and manually tracking models throughout the development process, resulting in long release cycles (it may take between 6 to 12 months to deliver a model to production). The long model development cycle hinders the ability for them to quickly adapt to emerging threats and to dynamically mitigate the associated risks. The major challenge FSIs face in this paradigm is reducing model development-to-production time without doing so at the expense of governance and regulations or contributing to an even more fragile data science ecosystem.
MLflow is the de facto standard for managing the machine learning lifecycle by bringing immutability and transparency to model development, but is not restricted to AI. A bank’s definition of a model is usually quite broad and includes any financial models from Excel macros to rule-based systems or state-of-the art machine learning, all of them that could benefit from having a central model registry provided by MLflow within Databricks Unified Data Analytics Platform.
Reproducing model development
In this example, we want to train a new model that predicts stock returns given market indicators (such as S&P 500, crude oil and treasury bonds). We can retrieve “AS OF“ data in order to ensure full model reproducibility and audit compliance. This capability of Delta Lake is commonly referred to as “time travel“. The resulting data set will remain consistent throughout all experiments and can be accessed as-is for audit purposes.
DESCRIBE HISTORY market_return; SELECT * FROM market_return TIMESTAMP AS OF '2020-05-04'; SELECT * FROM market_return VERSION AS OF 2;
In order to select the right features in their models, quantitative analysts often navigate between Spark and Pandas dataframes. We show here how to switch from a pyspark to python context in order to extract correlations of our market factors. The Databricks interactive notebooks come with built-in visualisations and also fully support the use of Matplotlib, seaborn (or ggplot2 for R).
factor_returns_pd = factor_returns_df.toPandas() factor_corr = factor_returns_pd.corr(method='spearman', min_periods=12)

Assuming our indicators are not correlated (they are) and predictive of our portfolio returns (they may), we want to log this graph as evidence to our successful experiment. This shows internal audit, model validation functions as well as regulators that model exploration was conducted with highest quality standards and its development was led with empirical results.
mlflow.log_artifact('/tmp/correlation.png')
Training models in parallel
As the number of instruments in our portfolio increases, we may want to train models in parallel. This can be achieved through a simple Pandas UDF function as follows. For convenience (models may be more complex in real life), we want to train a simple linear regression model and aggregate all model coefficients as a n x m matrix (n being the number of instruments and m the number of features derived from our market factors).
schema = StructType([
StructField('ticker', StringType(), True),
StructField('weights', ArrayType(FloatType()), True)
])
@pandas_udf(schema, PandasUDFType.GROUPED_MAP)
def train_model(group, pdf):
X = np.array(pdf['features'])
X = sm.add_constant(X, prepend=True)
y = np.array(pdf['return'])
model = sm.OLS(y, X).fit()
w_df = pd.DataFrame(data=[[model.params]], columns=['weights'])
w_df['ticker'] = group[0]
return w_df
models_df = x_train.groupBy('ticker').apply(train_model).toPandas()
The resulting dataset (weight for each model) can be easily collected back to memory and logged to MLflow as our model candidate for the rest of the experiment. In the below graph, we report the predicted vs actual stock return derived from our model for Ecopetrol S.A., an oil and gas producer in Columbia.

Our experiment is now stored on MLflow alongside all evidence required for an independent validation unit (IVU) submission which is likely a part of your model risk management framework. It is key to note that this experiment is not only linked to our notebook, but to the exact revision of it, bringing independent experts and regulators the full traceability of our model as well all the necessary context required for model validation.
Monte Carlo simulations at scale with Apache Spark
Value-at-risk is the process of simulating random walks that cover possible outcomes as well as worst case (n) scenarios. A 95% value-at-risk for a period of (t) days is the best case scenario out of the worst 5% trials. We therefore want to generate enough simulations to cover a range of possible outcomes given a 90 days historical market volatility observed across all the instruments in our portfolio. Given the number of simulations required for each instrument, this system must be designed with a high degree of parallelism in mind, making value-at-risk the perfect workload to execute in a cloud based environment. Risk management is the number one reason top tier banks evaluate cloud compute for analytics today and accelerate value through the Databricks runtime.
Creating a multivariate distribution
Whilst the industry recommends generating between 20 to 30 thousands simulations, the main complexity of calculating value-at-risk for a mixed portfolio is not to measure individual assets returns, but the correlations between them. At a portfolio level, market indicators can be elegantly manipulated within native python without having to shift complex matrix computation to a distributed framework. As it is common to operate with multiple books and portfolios, this same process can easily scale out by distributing matrix calculation in parallel. We use the last 90 days of market returns in order to compute todays’ volatility (extracting both average and covariance).
def retrieve_market_factors(from_date, to_date):
from_ts = F.to_date(F.lit(from_date)).cast(TimestampType())
to_ts = F.to_date(F.lit(to_date)).cast(TimestampType())
f_ret = spark.table(market_return_table) \
.filter(F.col('date') > from_ts) \
.filter(F.col('date') <= to_ts) \
.orderBy(F.asc('date'))
f_ret_pdf = f_ret.toPandas()
f_ret_pdf.index = f_ret_pdf['date']
f_ret_pdf = f_ret_pdf.drop(['date'], axis=1)
return f_ret_pdf
We generate a specific market condition by sampling a point of the market's multivariate projection (superposition of individual normal distributions of our market factors). This provides a feature vector that can be injected into our model in order to predict the return of our financial instrument.
def simulate_market(f_ret_avg, f_ret_cov, seed):
np.random.seed(seed = seed)
return np.random.multivariate_normal(f_ret_avg, f_ret_cov)
Generating consistent and independent trials at scale
Another complexity of simulating value-at-risk is to avoid auto-correlation by carefully fixing random numbers using a ‘seed’. We want each trial to be independent albeit consistent across instruments (market conditions are identical for each simulated position). See below an example of creating an independent and consistent trial set - running this same block twice will result in the exact same set of generated market vectors.
seed_init = 42 seeds = [seed_init + x for x in np.arange(0, 10)] market_data = [simulate_market(f_ret_avg, f_ret_cov, s) for s in seeds] market_df = pd.DataFrame(market_data, columns=feature_names) market_df['_seed'] = seeds
In a distributed environment, we want each executor in our cluster to be responsible for multiple simulations across multiple instruments. We define our seed strategy so that each executor will be responsible for num_instruments x ( num_simulations / num_executors ) trials. Given 100,000 Monte Carlo simulations, a parallelism of 50 executors and 10 instruments in our portfolio, each executor will run 20,000 instrument returns.
# fixing our initial seed with today experiment
trial_date = datetime.strptime('2020-05-01', '%Y-%m-%d')
seed_init = int(trial_date.timestamp())
# create our seed strategy per executor
seeds = [[seed_init + x, x % parallelism] for x in np.arange(0, runs)]
seed_pdf = pd.DataFrame(data = seeds, columns = ['seed', 'executor'])
seed_sdf = spark.createDataFrame(seed_pdf).repartition(parallelism, 'executor')
# evaluate and cache our repartitioning strategy
seed_sdf.cache()
seed_sdf.count()
We group our set of seeds per executor and generate trials for each of our models through the use of a Pandas UDF. Note that there may be multiple ways to achieve the same, but this approach has the benefit to fully control the level of parallelism in order to ensure no hotspot occurs and no executor will be left idle waiting for other tasks to finish.
@pandas_udf('ticker string, seed int, trial float', PandasUDFType.GROUPED_MAP)
def run_trials(pdf):
# retrieve our broadcast models and 90 days market volatility
models = model_dict.value
f_ret_avg = f_ret_avg_B.value
f_ret_cov = f_ret_cov_B.value
trials = []
for seed in np.array(pdf.seed):
market_features = simulate_market(f_ret_avg, f_ret_cov, seed)
for ticker, model in models_dict.items():
trial = model.predict(market_features)
trials.append([ticker, seed, trial])
return pd.DataFrame(trials, columns=['ticker', 'seed', 'trial'])
# execute Monte Carlo in parallel
mc_df = seed_sdf.groupBy('executor').apply(run_trials)
We append our trials partitioned by day onto a Delta Lake table so that analysts can easily access a day’s worth of simulations and group individual returns by a trial Id (i.e. the seed) in order to access the daily distribution of returns and its respective value-at-risk.

With respect to our original definition of data being a core asset (as opposition to being a cost), we store all our trials enriched with our portfolio taxonomy (such as industry type and country of operation), enabling a more holistic and on-demand view of the risk facing our investment strategies. These concepts of slicing and dicing value-at-risk data efficiently and easily (through the use of SQL) will be covered in our part 2 blog post, focused more towards a risk analyst persona.
Getting started with a modern approach to VaR and risk management
In this article, we have demonstrated how banks can modernize their risk management practices by efficiently scaling their Monte Carlo simulations from tens of thousands up to millions by leveraging both the flexibility of cloud compute and the robustness of Apache Spark. We also demonstrated how Databricks, as the only Unified Data Analytics Platform, helps accelerate model development lifecycle by bringing both the transparency of your experiment and the reliability in your data, bridging the gap between science and engineering and enabling banks to have a more robust yet agile approach to risk management.
Try the below on Databricks today! And if you want to learn how unified data analytics can bring data science, business analytics and engineering together to accelerate your data and ML efforts, check out the on-demand workshop - Unifying Data Pipelines, Business Analytics and Machine Learning with Apache Spark™.
VaR and Risk Management Notebooks:
https://databricks.com/notebooks/00_context.html
https://databricks.com/notebooks/01_market_etl.html
https://databricks.com/notebooks/02_model.html
https://databricks.com/notebooks/03_monte_carlo.html
https://databricks.com/notebooks/04_var_aggregation.html
https://databricks.com/notebooks/05_alt_data.html
https://databricks.com/notebooks/06_backtesting.html
Contact us to learn more about how we assist customers with market risk use cases.
--
Try Databricks for free. Get started today.
The post Modernizing Risk Management Part 1: Streaming data-ingestion, rapid model development and Monte-Carlo Simulations at Scale appeared first on Databricks.
Dont Acquire a Company Until You Evaluate its Data Quality
Mergers & acquisitions happen when companies believe they are more valuable together than when operating separately. The companies join workforces, systems, infrastructure, and data to become a new, more powerful, more valuable, more effective entity. That is only until they realized they overlooked or underestimated the key issues with data, IT infrastructure & integration plans. In fact, most merger and acquisition plans fail miserably because of data integration challenges.Save yourself the devastating cost of a failed merger. Do not acquire a company until you evaluate its data infrastructure and adherence to quality.Why the Emphasis on Data Quality? As of 2019, the value of global M&A deals stands at 3.9tr USD. Ironically, another report concludes that up to 90% of mergers fail to meet their goals.While there are many factors to this failure (with most of it being subjective to a company’s culture, budget, infrastructure etc), we’ve seen the lack of data due diligence as the most common reason of migration failure.The problem with data quality isn’t new. However, as the world moves towards harnessing big data to make important decisions, it’s imperative for companies to understand the risks of neglecting data quality. Most companies focus on data quality as a ...
Read More on Datafloq
Read More on Datafloq
Facebook renames its Calibra cryptocurrency wallet as Novi
The Novi digital wallet set to launch when Libra coins debut promises to give Facebook opportunities to build financial services into its offerings
Tuesday, 26 May 2020
MLOps takes center stage at Spark + AI Summit
As companies ramp up machine learning, the growth in the number of models they have under development begins to impact their set of tools, processes and infrastructure. Machine learning involves data and data pipelines, model training and tuning (i.e., experiments), governance, and specialized tools for deployment, monitoring and observability. About three years ago, we started to first hear of “machine learning engineer” as a role emerging in the San Francisco Bay Area. Today, machine learning engineers are more common, and companies are beginning to think through systems and strategies for MLOps — a set of new practices for productionizing machine learning.

Featured MLOps-focused Programs and Topics
The growing interest in Devops for machine learning or MLOps is something we’ve been tracking closely and, for the upcoming virtual Spark + AI Summit, we have training, tutorials, keynotes and sessions on topics relevant to MLOps. We provided a sneak peek during a recent virtual conference focused on ML platforms, and we have much more in store at the conference in June. Some of the topics that will be covered in the virtual Spark + AI Summit include the following:
- Model development, tuning and governance: There will be hands-on training focused MLflow and case studies from many companies, including Atlassian, Halliburton, Zynga, Outreach and Facebook.
- Feature stores: In 2017, Uber introduced the concept of a central place to store curated features within an organization. Since the creation and discovery of relevant features is a central part of the ML development process, teams need data management systems (feature stores) where they can store, share and discover features. At this year’s summit, a set of companies, including Tecton, Logical Clocks, Accenture and iFoods, will describe their approach to building feature stores.
- Large-scale model inference and prediction services: Several speakers will describe how they deploy ML models to production, including sessions that detail best practices for designing large-scale prediction services. We will have speakers from Facebook, LinkedIn, Microsoft, IBM, Stanford, ExxonMobil, Condé Nast and more.
- Monitoring and managing models in production: Model monitoring and observability are capabilities that many companies are just beginning to build. At this year’s virtual summit we are fortunate to have presentations from companies and speakers who are building these services. Some of the companies presenting and teaching on these topics include speakers from Intuit, Databricks, Iguazio and AWS.
- MLOps: Continuous integration (CI) and continuous deployment (CD) are well-known software engineering practices that are beginning to influence how companies develop, deploy and manage machine learning models. This year’s summit will have presentations on CI/CD for ML from leading companies, including Intel, Outreach, Databricks and others.
Machine learning and AI are impacting a wider variety of domains and industries. At the same time, most companies are just beginning to build, manage and deploy machine learning models to production. The upcoming virtual Spark + AI Summit will highlight best practices, tools and case studies from companies and speakers at the forefront of making machine learning work in real-world applications.
--
Try Databricks for free. Get started today.
The post MLOps takes center stage at Spark + AI Summit appeared first on Databricks.
Medical Internet of Things: Growth Prospects of IoT Solutions in Healthcare
Healthcare is rightfully considered one of the most promising industries for IoT technology implementation. This is the industry where many routine processes can be automatized with the help of IoT-based solutions. This, in turn, enhances the efficiency of the workflow in hospitals and clinics. Let’s find out how the Medical Internet of Things works and why it is worth using.
Why Use IoT in Healthcare
The main idea of the IoT concept is collecting, transferring, and/or processing data without human participation. There are plenty of ways to make use of this technology in healthcare. Thus, automatic collection of physical health data and its instant transferring to specialists helps in making a diagnosis, disease prevention, and remote monitoring. EHR systems help keep medical records in order and provide instant personalized access to medical data.
Internet of Medical Things
As the name implies, the Internet of Medical Things is a smart system consisting of interconnected devices. Usually, these networks include such smart devices as smart bracelets/watches, trackers, monitoring devices, and so on. The tasks performed by these devices can be divided into two groups: collecting data and monitoring. As of now, IoMT is one of the fastest-growing healthcare sectors.
What Are the Benefits of IoT Solutions in ...
Read More on Datafloq
Why Use IoT in Healthcare
The main idea of the IoT concept is collecting, transferring, and/or processing data without human participation. There are plenty of ways to make use of this technology in healthcare. Thus, automatic collection of physical health data and its instant transferring to specialists helps in making a diagnosis, disease prevention, and remote monitoring. EHR systems help keep medical records in order and provide instant personalized access to medical data.
Internet of Medical Things
As the name implies, the Internet of Medical Things is a smart system consisting of interconnected devices. Usually, these networks include such smart devices as smart bracelets/watches, trackers, monitoring devices, and so on. The tasks performed by these devices can be divided into two groups: collecting data and monitoring. As of now, IoMT is one of the fastest-growing healthcare sectors.
What Are the Benefits of IoT Solutions in ...
Read More on Datafloq